Preliminaries
Data Preprocessing
In real life data, usually there will be missing values. Depending upon the context, missing values might be handled either via imputation or deletion.
Imputation: replaces missing values with estimates of their values
Deletion: simply discards either those rows or those columns that contain missing values.
Linear Model
Linear Regression
Leanr Regression Model can be represented as $\hat{y} = Xw + b$, where $X$ is in the shape of $[\text{batch_size}, \text{num_features}]$, $w$ is in the shape of $[\text{num_features}, 1]$, b is a scale value. Correspondingly, $\hat{y}$ is in the shape of $[\text{batch_size}, 1]$
Linear Regression Model usually use Mean Square Loss as loss function
Linear Regression Model as analytic solution, which is $w^{*} = (X^{T}X)^{-1}X^{T}y$ ## Logistic Regression Logistic Regression is a binary classification model. Basicaly, it adds a sigmoid function on the output of Leaner Regression Model, $\sigma(x) = \frac{1}{1 + e^{-x}}$, the output value is bounded to $[0, 1]$ ## Softmax Regression Softmax Regression is a multi-classification model. In the final layer, there will be multiple output nodes which normally will be the same as the number of classes. For the output nodes, we apply softmax function: $$ \hat{y} = softmax(o) \space \text{where} \space \hat{y_i} = \frac{exp(o_i)}{\sum_{j}exp(o_j)} $$ The output value of softmax can be treated as the probability. For the label, we use **one-hot encoding** and use **Cross Entropy Loss**: $$ l(y, \hat{y}) = -\sum_{j=1}^{q} y_i \log \hat{y_i} $$ # Accuracy of Classification Model accuracy is simple way to evaluate the performance of classification model, it is simply calculated by the number of right perdiction divide by the number of total predictions. # MLP Multilayer Perceptrons is based on linear model with hidden layers and activation functions. The activation functions is to introduce nonlinear to the model. If there is no activation function, the MLP will still be a linear model. Usually, we use `ReLU` as activation function. # Dropout Dropout is a method to prevent overfitting. Dropout will random set some paramater value of a layer to zero with probability of $p$, and in order to keep the the distribution of the data unshifted, we need to scale those remain parameter to $\frac{h}{1-p}$. Dropout is usuallly applied after activation functions. Dropout is only used during training steps, there will be no drop out in inference step. # Weight Decay Like Dropout, Weight Decay is a way to prevent overfitting. It is basically add $l2$ penalty to the **loss function**, it is defined as $$ \frac{\lambda}{2}||W||^2 $$ $\lambda$ is called **Weight Decay Rate**. In pytorch, weight decay is set upon optimizer. # CNN # Convolutional Operation In the two-dimensional Convolutional(cross-correlation) operation, we begin with the convolution window positioned at the upper-left corner of the input tensor and slide it across the input tensor, both from left to right and top to bottom. When the convolution window slides to a certain position, the input subtensor contained in that window and the kernel tensor are multiplied elementwise and the resulting tensor is summed up yielding a single scalar value. For input tensor with size $n_h \times n_w$ and convultional kernal size $k_h \times k_w$, the output tensor size is $(n_h - k_h + 1) \times (n_w - k_w +1)$ For a convolutional Layer, it usually has bias parameter like the linear model. The size of bias parameter is number of output channel. The kernal can be learned based on input value and output value. The output tensor of the convolutional layer is also called feature map. In the deep cnn neural network, the feature map close to the data input usually has smaller receptive field, representing some local spatial features(i.e. edges, corners). While the feature map in deep layer usually has larger receptive field, representing gobal spatial features or semantic features(i.e class information). ## Padding and Stride * padding: the convolutional op will reduce tensor size, in order to keep the size unchanged, we can padding zeros around the input, if the kernel size is $k_h \times k_w$, usually, we will padding $(k_h - 1) / 2$ on top and bottom, padding $(k_w - 1)/2$ on left and right. Hence, we often use odd sized convolutional kernel. * stride: stride is mainly used for reduce tensor size. Defaultly, convolutional layer use stride of 1, which means the kernel window moves one element next after the convolutional operation. stride size can be set both in height and width. Usually, we will set stride to 2 to downsampling the tensor size to half both in height and width. ## Pooling * max pooling: output the max value in the kernel area * average pooling: output the avage value in the kernel area Pooling layer has no learning parameter. In Deep CNNs, the Convolutional Layer usually will use padding to keep the height and width unchanged but extend output channels to double. While Pooling Layer is usually set with stride equal to 2 to half the width and height. In pytorch, the stride size by default is equal to kernel size. ## Multiple Input Output Channels usually image has three channels(rgb) and for a convolutional layer, it can have multiple output channels. If the input channels is $c_i$ and output channels is 1, then we need $c_i$ cnn kernels, the result will be the sum of convolutional(cross-correlation) operation result of input channel $i$ and convolutional kernal $i$. Correspondingly, if the input channels is $c_i$ and output channels is $c_o$, the there will be $c_i \cdot c_o$ number of cnn kernels The channel dimension can be considered as the feature dimension of convolutional nerual networkLeNet
The first Deep CNN.
1 | self.net = nn.Sequential( |
Modern CNN
AlexNet
AlexNet is basically a bigger and deep version of LeNet.
1 | self.net = nn.Sequential( |
VGG
VGG provide a general template to design convolutional nerual network which is use net blocks. In VGG, the layers in a block are basic Conv Layer, Activation Layer and Pooling Layer
block code
1 | def vgg_block(num_convs, out_channels): |
net structure
1 | conv_blocks = [] |
NiN(Network in Network)
NiN Replaces the Full Connect Layers in CNN with Global Avg Pool, which significant reduces training parameters.
NiN block:
1 | def nin_block(out_channels, kernel_size, stride, padding): |
NiN net structure
1 | self.net = nn.Sequential( |
GoogLeNet
GoogLeNet designed a multi-branch structure called Inception Block
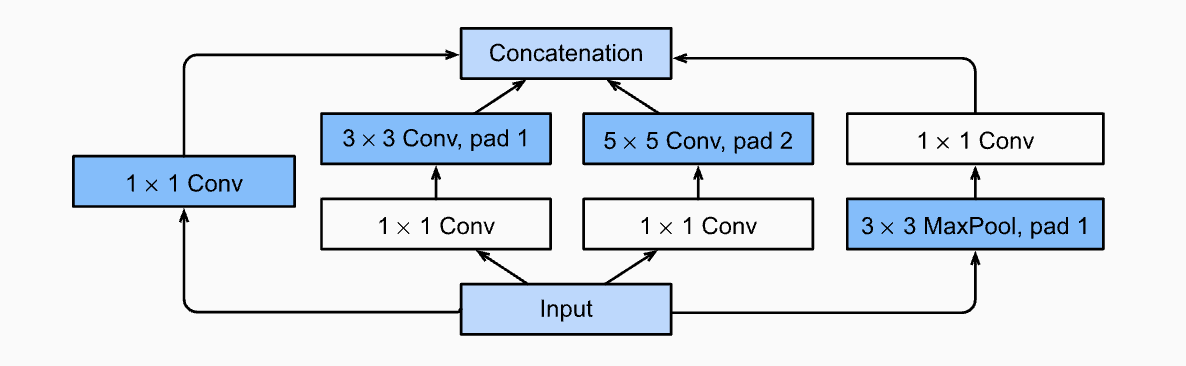
for the input, it use different size of convolutional kernels to extract new features and contact the result of all branchs in feature dimension. In order to do contatenation sucessfully, the output height and width of each branch should be the same.
The each branch in inception block keep the height and width the same as the input. While during blocks, it use pooling layer to half height and width.
Moreover, in the final layer, it use a single full connect layer simply to match the output with number of classes.
GoogLeNet structure:
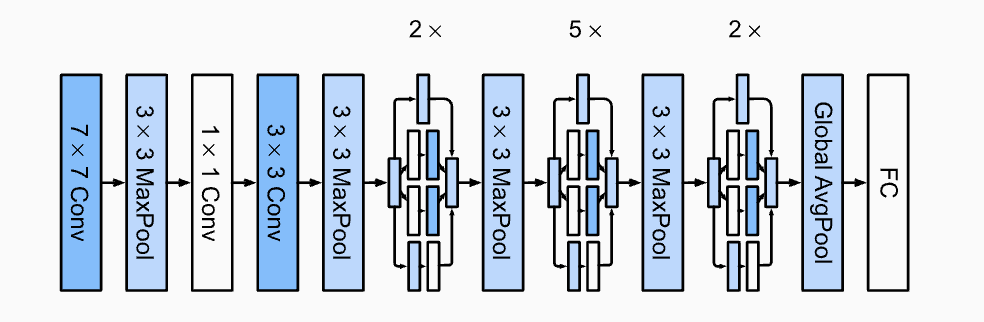
ResNet
ResNet is a net that will add input back into output for each block
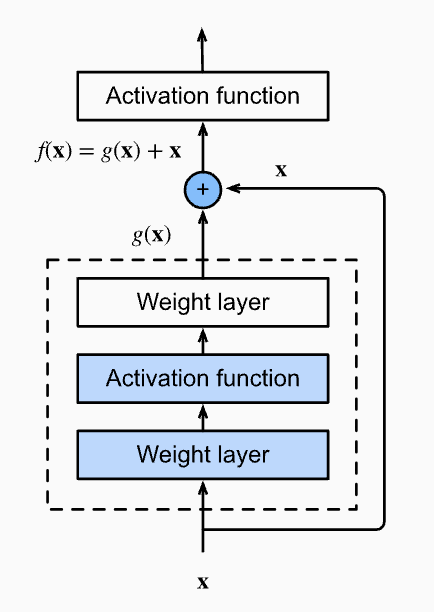
Perplexity
Basically, perlexity is the exponential value of cross entropy loss. We can use perlexity to evaluate the performance of a lanuage model. During training step we still the result of cross entropy loss to calculate the gradients and update parameters. The cross entropy loss ranges in $[0, +\infty]$, so the perplexity ranges in $[1, +\infty]$.
Modern RNN
LSTM & GRU
LSTM and GRU are RNN models with more complex hidden states, they mainly design to prevent gradient exploding in training rnn.
Deep RNN
deep rnn increase the number of layers of hidden states.
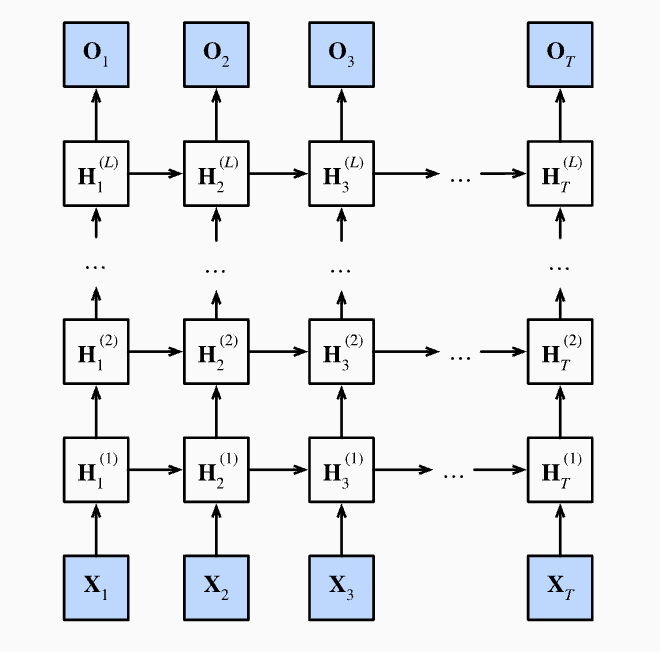
As depicted in the graph, Hidden state is computed by:
To use deep rnn in pytorch, we only need to simply use the num_layers parameter
1 | nn.RNN(input_size=vocab_size, hidden_size=32, num_layers=4) |
Bidirectional RNN
In Bidirectional RNN, in each hidden layer, there is a hidden state calculated from $t_1$ to $t_n$ and a hidden state calculated from $t_n$ to $t_1$, after that, we concat the hidden state in horizontal direction. As a result, the final output size of hidden state is the double of each hidden state size.
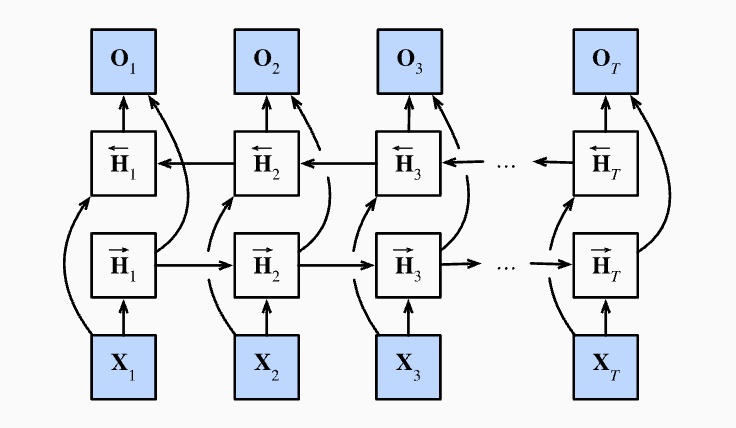
A trick to calculate hidden state from $t_n$ to $t_1$ is to reverse input $X$ to $X_t$ to $X_1$ and then do calculated like normal input, this can speed up calculate instead of use for loop from $t$ to $1$.
Bidirectional RNNs are mostly useful for sequence encoding and the estimation of observations given bidirectional context.
Bidirectional RNNs are very costly to train due to long gradient chains.
Bidirectional RNNs are not quite useful in predicting next token by given tokens, as there are only information from past was given during prediction.