问题引出
在多分类问题中,一些分类器是利用多个二分类器来做分类的,有些模型则能直接进行多分类学习。softmax-regression就是一种能够直接进行多分类学习的线形分类模型(虽然叫regression,但本身是分类模型)。
one-hot encoding
对于多分类学习任务,我们通常会把可能的分类结果种类用数字来表示,例如对于一个可能有3种分类结果的学习任务,我们可以使用${1, 2, 3}$来分别表示第一类到第三类。如果使用这个自然序编码来对分类结果种类进行编码,那么对于每一个训练样本,我们需要的输出就只有一个。
使用自然序编码时,如果分类结果之间本身没有自然序的关系, 对于模型的输出和样本真实的标签之间的距离将不好表示。例如对于某个样本来说,模型的输出结果是1,表示第二类,但样本真实的标签为3,表示第3类,此时如果将距离定义为$|1-3| = 2$,这在分类结果之间本身没有自然序的关系的情况下显然是不太合理的。
另外一种表示分类结果的方法就是one-hot encoding。one-hot encoding将每一种分类结果用一个向量表示,例如,还是对于一个可能有3种分类结果的学习任务,我们可以使用${ {1, 0, 0}, {0, 1, 0}, {0, 0, 1} }$来分别表示第一类到第三类,这样每个种类之间可以看作是没有直接关系的(种类的表示向量之间两两正交)。
所以,对于种类之间有自然序关系的分类学习任务,可以使用自然序来对结果进行编码。但是如果种类之间没有自然序关系,应该尽量使用one-hot encoding。
softmax-regression模型使用的就是one-hot encoding来对分类结果进行表示。
softmax-regression 网络结构
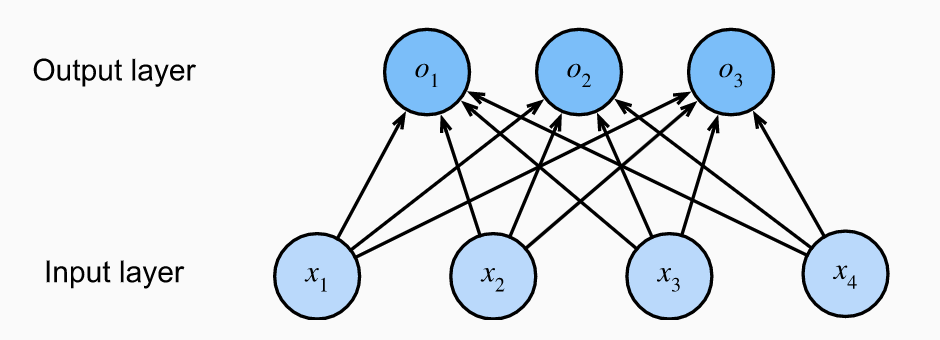
对于一个有n个输入特征,m个可能分类结果的网络来说,其结构为:
由此可见一个softmax-regression网络是一个单层的全连接网络。
softmax函数
在softmax-regression的网络中,我们可将每个输出看作一个样本可能是某一类别的概率,输出结果最大的那个就是最有可能的分类结果。但是最为概率,就需要输出的值位于$[0, 1]$之间,并且所有值之和为1。这对于使用线形模型的输出来说有些困难。所以为了保证让网络输出的结果能够作为概率,需要对输出作为进一步处理,保证输出的结果必须为非负并且和为1。softmax函数就是一个这样的函数:
虽然softmax函数不是一个线性函数,但是softmax-regression的输出仍然是由输入特征的线形变换(仿射变换)决定的,所以softmax-regression仍然是一个线形模型。交叉熵损失(Cross Entropy Loss)
交叉熵是一个信息论中的概念,它衡量了预测的概率分布和真实的概率分布之间的差异。在softmax-regression中,可以将网络预测的输出看作预测的概率分布,将样本的真实类别对应的ont-hot编码看作是真实概率分布,这样就可以定义模型的损失函数了。其定义如下:
训练
有了模型和损失函数后,就可以使用随机梯度下降法(Stochastic Gradient Descent)对模型进行训练了。
1 |