has yet to do xxx = has not yet to do xxx,都表示还没有做xxx
特殊过去式和过去分词:
become:became,become(过去分词是原型)
read: read, read (过去式和过去分词都是原形)
creep: crept或creeped, crept或creeped
By + 时间节点,要用完成时,根据具体语境判断是用过去完成时还是将来完成时
manage to do something:设法完成了某事
强调句:It is/are/was/were + (被强调部分) + that + (其他部分)
一定程度:to an extent
little more than:表示“仅仅”的意思,因为是little,不是a little
A 怎么怎么样 despite B 怎么怎么样:尽管B 怎么怎么样,但是A怎么怎么样
IELTS-Reading
基本常识
考试时间:60分钟
文章数量:3篇
题目数量:40道(13+13+14)
文章字数:1200-1500 words/p
题型:
图标填空题型
完成句子题型
摘要题型
简答题型
判断题型
配对题型
标题对应题型
选择题型
评分标准
9分——对39到40个
8.5分——对37到38个
8分——对35到36个
7.5分——对33到34个
7分——对30到32个
6.5分——对27到29个
6分——对23到26个
句子/笔记填空
题型特点
原文原词填空(不改形式,连续选词)
顺序题目(偶尔小乱序)
答案位置可能集中(几个段落),可能分散(全文)
解题步骤
审题目要求:字数要求,在符合题目要求的前提下,保持字数最大化,如超过字数要求,去掉修饰词,保留核心词
在题干中划定位词,回原文中定位
大定位
- 名词
精准定位
冠词
否定词
逻辑关系词
介词
动词
预判答案
名词占到80%,动词占10%,形容词、副词、数词共占10%
名词:预测是填专有/特殊/普通名词,单数/复数,人/物
- 空前有known as / called / named / refer to as 一般填专有/特殊名词
动词:预测原形/过去式/ing形式
注意:答案形式没有动词+名词
可从最容易定位、最简单的题目开始做,然后再往前往后找
摘要填空
该题目是一小段文字,是整篇文章或原文中的几个段落主要内容的缩写或改写,按照范围,摘要可分为两种:全文摘要和部分段落摘要。
全文摘要(20%):题目标题与原文标题相似,题数较多
部分段落摘要(80%):标题区别较大,题数较少。
有单词列表的摘要填空
题型特点
顺序性(偶尔小乱序,很少)
选项特点
原文单词
词性变化
同义词
语态变化
主要是否可以某个选项可以选多次
图表题
原理图(Diagram)
流程图(Flow Chart)
统计表(Table)
题型特点
图上的提示信息在文中通常会原词重现
答案常常集中于原文中的一个或者两个段落
原文原词填空,不要做任何修改
顺序题目(小范围乱序,很少)
判断题
题型特点
顺序性:题干顺序与原文顺序基本一致,可以认为没有乱序
题目在原文中的分布是不均匀的,可能出现跨段出题
解题步骤
在题干中选择至少两个定位词回文中定位
定位句一般为一到两个句子
一次划两个题目的定位词去文中找可以加快做题速度
选True的一般情况:
题目是原文的原意表达,使用原词或者同义替换改写,通常运用同义词或同义结构
题目是对原文信息的概括或归纳总结(出现的情况很少)
题目是对原文相邻的两个句子或同一段落中上下文信息的归纳总结
题目是对原文中不同自然段中的信息归纳总结
选False的一般情况:
使用反义词或者表达意思相反
绝对陈述
选Not Given的情况:
原文中无法找到定位句
可以找到定位句,到是无法得出相关信息,可能成立可能不成立
配对题
单词-句子配对题
题干是单词,选项是句子 or 题干是句子,选项是单词
解题思路
- 单词有顺序性(题干是单词就根据题干回原文中找,选项是单词就根据选项从原文中找),出题范围是全文,如果单词是人名的话,在文中可能在前面出现一次完整的人名后,在后面使用人名简写,要注意
- 可以先看下选项和题目的个数,明确是否有多余选项(选项个数大于题目个数)或者是否一定会有重复选择(选项个数小于题目个数)的情况
半句配对题
题干是句子的一半,选项也是句子的一半
解题思路
- 题干大部分都有顺序性,出现乱序的情况较少
段落信息配对题
题干是句子,题目问句子对应文章中的哪一段
题目特点
- 题目完全乱序
同义替换较复杂
多数情况下是题目只对应段落中的一个句子,也有少数题目对应段落中多个句子
解题步骤与技巧
此类题型最后做,一般会与其他题型有交叉重合出题点
做题顺序:可以不按照题号顺序
先做特征明显的,映像深刻的
剩余题目按照文章段落顺序寻找答案
重点看未出过题的段落
分类配对题
题干是句子,题目让选择对应的类别——A类、B类、A类和B类都是,A类和B类都不是
题目特点
小范围乱序
出题位置比较集中
解题步骤与技巧
用选项大定位(确定出题段落)
划出题干关键字,去文中定位,分辨主语
主旨题
选标题
题干是段落序号,选项是段落主旨大意
题型特点
- 完全乱序
出题位置特殊,如果出的话一定是文章的第一题
选项较多,具有干扰选项(选项数量超过题目数量)
两种类型:paragraph(给每一个小段选一个主旨,大多数情况是这种类型);section(多个段落合起来选一个主旨),当类型为paragraph类型时,不一定要给每一段都选,注意看题目
解题思路
最后做这种题,该题不会和段落信息配对题一起出现在一篇文章中
60%的段落会有主旨句,主旨句一般出现在段落的第一句、第二句或最后一句
选择题
选择题有多种类型,按形式划分可以分为:单选(4选1)和多选(5选2、7选3、10选5),按内容划分可以分为:细节型和总结型
单选题型特点
属于顺序题型,一段一题或一段两题
题目有时会告诉是在那段出题,出题位置也有可能在introduction段(标题和主体内容之间的一段用于说明的文字)
如果题目中出现原文原词的,大概率会是错误答案
多选题特点
按答对个数给分
答案在文中出现的位置通常是密集的
如果题目中出现原文原词的,大概率会是错误答案
做题心得
那些最后做的题(段落信息配对、主旨题)不一定要所有都最后做,建议提前画好关键词,可以边看边做一些明显的题,等到最后再来做那些不太好确定的题
看清题目,到底是说xxx是好的还是不好的(是advantage还是disadvantage,是practical还是impractical)
IELTS-Writing
基本常识
雅思写作分有两个task,task 1是图表题,task 2是议论题。写作考试时间为60分钟。task 1一般花20分钟(task 1占总分的1/3),task 2一般花40分钟(task 2占总分的2/3)。
Task 1:小作文
简介
task 1 为图表题,一般有6种小题型,分为两大类:
第一类:数据类—— line chart、pie chart、bar chart、table
第二类:描述类—— flow chart、map
第一类小作文写作方式
第一类一般分为4-5段:
开头段
overview段
主体段1
主体段2
主体段3(optional)
开头段
根据题目进行改写即可,能换则换,做到中规中矩(不追求写的很好),不抄题,不出语法错误。
步骤:
改图描述了xxx
the graph/diagram/chart (line chart / pie chart / bar chart / flow chart / flow chart / map)
不要写below/above
描述 show=compare=illustrate=demonstrate=give us the information of(最好的替换词就是compare和illustrate——考官说的)
混合图需要对每个图都进行说明
given is a xxx chart that illustrate xxx
主体结构能改则改
- 主动换被动/复杂结构(从句)/ 名词动词词性转换
地点概述、列举即可(题目概述你列举,题目列举你概述)
- in the four countries (including)
- in terms of four distinct ways
- namely xxx, xxx
时间
between … and … = from … to
during … years/during the period from … to …/during the period shown/in a period spanning xxx years
overview段
- 概述主要内容或主要变化,显而易见的不需要进行写出
不要提到具体数据,使用一些概括性的描述(xxx是最大、xxx是最小、xxx上升非常多、……)
尽量去描述大范围的概括性,尤其是对于静态图,例如有两个图标,有一些共同的特征,可以将两个图表放在一起概括而不是分别概括
开头句式:It is clear that … / It is noticable that … / Overall, …
主体段
分段方式
- 混合图99%的情况下都是一图一段
在各个图例都很类似的情况下可以按照年份划分,如果图例差别较大,首先按照相似的几个划为一类来分
要点
数据排列的顺序:从小到大/主要到次要,不可以跳跃式
篇幅的占比:不要过度关注细节,主要内容用复杂句式结构,次要信息合并描写
衔接手段:段落间有衔接(词、短语、一句话),句子间有衔接(similarly,by contrast,on the contrary,however, while, whereas)
指代:避免重复,使用代词替换,或者用从句加代词(which is less than that in …)
词汇多样性:避免重复用一个单词表达一个意思
句式多样性:无语法错误前提下,使用复杂结构(there be句式、被动语态、定语从句、分词做状语、让步状语从句(尽管…,即使…))
注意时间、时态、最大值、单位
数据支持:作文中提到的数据最好要超过题目中的一半以上
用于描述趋势的词/短语
上升:increase/rise/grow/soar(急剧上升)
下降:decrease/decline/fall/drop/plummeted
保持不变:level off/remain stable/remain constant
波动:fluctuate
用于描述幅度的词/短语
sharp/dramatic/steep/significant
gradual/moderate/modest/slight
线性图变化趋势描述句型
there be + adj + n:there was a steep increase in sales of convenience food.
verb + adverb: Sales of convenience food increased steeply
something/year saw a xxx
内容
线图可以写的内容
点=起点、终点、最值、交点(数据不多的情况下起点可以自成一段)
起点:数据不多的情况下,起点一般单独一段
终点:一般融在线里描写,如decrease to 9
最值:最大值一般单独写一句话(最小值视情况),有时半句
交点:一般不单独出现,写在线里
线=趋势+幅度
趋势:上升、下降、波动、稳定
幅度:大幅度/小幅度
线与线=关系
相似-用连接词连接(smilarly)
相反-用衔接词连接(by contrast)
交叉-用超过表达=overtake/surpass
第一类小作文常用同义表达
表示“大约”
approximately
about
around
roughly
表示“是最大”
provided the most xxx
ranked at first
对于售卖可以用:become the best selling xxx
接数据的一些表达
to xxx
peaking at xxx
reaching xxx
with xxx
with approximately of xxx
连续提到多个数据的一些表达
- xxx and xxx each xxx
表示“花销”
- expenditure
- budget
- spending
表示相似/想反增长和下降趋势
experienced the same/opposite change inclinations inclinations
experienced similar/opposite tendencies of rises and falls
第二类小作文写作方式
流程图(flow chart)
和第一类一样,流程图写作也分为4到5段:
开头段(和第一类一样,都是改写题目)
overview段(不同于第一类,需要写如下内容)
写流程图包括几个步骤、从xxx开始到xxx结束,包含几个原材料(optional)
有多个图则需要每个图写包含几个步骤,从xxx开始到xxx结束
主体一段
主体二段(如果题目有两个流程图,自然按两个图进行分段,如果题目只有一个图,主题也要至少分为两段,分段一般是将前几个步骤分为一段,后几个步骤分为一段,需要视情况而定)
主体三段(optional)
要点:
- 使用一般现在时
不能使用祈使句(动词做主语),也不可以写成操作指南(we can xxx),所以99%都要使用被动语态
流程图中的词不能做同义替换
每句话之间一定要有连接词
流程图overview段短语
包括几个步骤:
consist of
is composed of x stages/steps
include
从…开始到…结束:starting from … and ending in ….
总之:overall,in summary, all in all
例句:
Overall, cement production consists of 5 stages, starting from crushing materials into powder and ending in bagging cement. In contrast, concrete production is simple, mixing four materials.
流程图表示阶段的短语
开始阶段
Firstly/First of all
To begin with
At the first stage
During the begining phase
The process starts from
次阶段
before、until、after
next、Secondly
at the next stage
the next step in the process is xxx
then
finally
the following stage is
流程图表示过程的短语
传送:
deliver
send
transfer
transport
转化
convert into
transform into
使用
utilize
use
流程图废话文学操作
在一些情况下流程图的流程比较简单,尤其是只有一个图的情况下,按照全流程写下来有时候可能不够150个字,可以用以下方法来扩写
选用复杂的顺序词
写废话
- as can be seen/observed
扩写overview段
the process 改写成the process of xxx
强行分为几个大步骤,每个大步骤分别说starting from xxx and ending in xxx
地图(map)
地图写作也分为4到5段:
开头段(和第一类一样,都是改写题目)
overview段(概括变化,简单提及一些重要变化即可)
主体一段
主体二段
主体三段(optional)
主体写作逻辑
先写新增的
再被代替的
然后写消失的
最后写扩建、减少的
地图写作常用词汇短语
make something bigger
extend
expand
make something new again/modern
renovate
modernise
take something away and put something else in its place
- replace
make something better
- improve
make something smaller
- reduce
build serveral buildings in an area where there was nothing
- develop
put in something totally new
- add
take something away
- remove
build something again
- reconstruct
表示数量增多/面积扩大
double
- The number of dwelling places doubled to 200
expand/extend/enlarge/develop/rise/grow/increase/improve
- Dwelling places was expanded to twice its size.
become/turn/get + bigger / larger / smaller
- Dwelling places become bigger
表示数量减少/面积缩小
reduce/decline/decrease/drop/fall/shrink
The number of A dropped by half
The size of A was reduced to only half of / one third of the original isze
Woods shrank in size
表示“替换”,即A消失+B出现
replace/remove/convert/give way to
A was replaced by B
A was removed
A was converted to B
A gave way to B
表示新增
build in/constructed in/add to
- A road was built in the north of the area
表示消失
- disappear/be no longer there
地图表示方位的时候,注意介词的使用
To 表示在外面的方位
In 表示在里面的方位
不太好的表达收集
The other four proportions between 2003 and 2013 from less to more is xxx, xxx, xxx, xxx
- 分析:这样表达没有提到数据,就是无效的表达,可以先说前两个数据,再说followed by 后两个数据
There located xxx, There saw xxx
- 分析:这样表达不太书面,记住在写作中用There的情况只有There be句型就行
from 210 to 810 and 200 to 800 thousand, respectively
- 改为from 210 and 200 to 810 and 800, respectively
小作文优秀例句摘抄
Samsung and Apple saw the biggest rises in sales over the 5-year period
The table compares the five highest ranking countries in terms of the number of visitors and money spent by tourists over a period of two years.
It is clear that France was the world’s most popular tourist destination. // 说数据不一定要说数据排第一,可以用其他符合语境的表达,这里就是是最受欢迎的旅游目的地。
2013 saw a rise of between 1 and 4 million tourist visitors to each country with the exception of China, which received 2 million fewer visitors than in the previous year.
Generally, the percentage of moviegoers from all ages experienced the same change inclination, despite minor fluctuations.
In the first 10 years, osillations of differing extends can be observed in the figures for all group
These figures were well over twice as high as those for any other country
UK residents spent a significantly larger percentage of their household budgets on leisure than their New Zealand counterparts.
In 1980, 29% of an avarage New zealand budget went on food and drink, while the equivalent figure for UK was 23%
Looking at the age profile pie chart, we can see that the majority of people attending evening lessons were over 40 years of age. To be precise, 42% of them were aged 50 or more and 26% were aged between 40 and 49.
The same increasing tendency was also witnessed by female full-time and students, xxx
小作文写作心得
- 写的时候不必太过于纠结一些描述的替换,如果想到了就换,没想到重复写也行,但是可以在重复的地方做些小标记,首先要关注于完成文章,完成文章后,如果有多的时间,再回去看重复的地方能否替换为其他的表达。
- 开头段一定要写全面(时间、地点、分类),如果时间不是连续的时间,而是几个离散的时间,可以用in xx separate years来概括。
- 小作文的Overview段最好能够写两句。
- 尽量多的使用连接词
Task 2:大作文
简介
task 2 为议论题,有四种小题型:
双边讨论:Discuss both views and give your opinion
单边选择:To What extend do you agree or disagree
利弊分析:Do advantages outweigh disadvantages ? / Is this a positive or negative development ?
说明文:What are the reasons ? what can be done to solve it?
双边讨论写作方法
双边讨论写作内容需要包括去分别描述两种观点+给出自己观点(自己的观点可以是偏好某一种观点或者是认为两种观点同等重要)
分段一般分为4到5段:
开头段:不能再改写题目,一般写两句话:话题引入+表达自己观点,表达自己的观点也要提及题目的两个观点,可以使用让步状语从句
主体段1:描写观点1,给出支撑观点1的理由
主体段2:描写观点2,给出支撑观点2的理由
主体段3 (optional):写自己的观点,如果在开头段和结尾段中给出了自己的观点,那么可以省略该段
结尾段:总结+给出自己的观点
开头段可用的句型
话题引入:
- whether xxx (and xxx) has/have aroused widespread controversy
表达自己观点:
in my opinion / in my point of view
as far as I am concerned
from my perspective
主体段写作方式
双边讨论主题段的写作通常都采用On the one hand, …, On the other hand,… 来分别引出两段。(在一段内表示两个方面可以用For one thing, xxx. For another, xxx)
每一个观点最好要给点例子,而且例子最好不要用太长的话,并且做好用国外的例子单边选择写作方式
单边选择只需要写出选择支持的一方的观点就行,不需要写出支持的另一方
利弊分析写作方式
利弊分析需要分为5段:如果认为利大于弊,则利需要写两段,弊写一段,反之亦然
大作文话题积累:
教育:引申出的话题:
现在的学业
未来的就业
学生的性格养成
教育平等 => 减少贫富差距 => 促进社会稳定
社交媒体/名人网红 对青少年行为的影响
相关词汇积累:
- education,career,character,unemployment rate,
政府: 引申出来的话题:
政府的权利与责任
权利:formulate policies,enact laws,impose taxes
责任:provide public services(education、healthcare、infrastructure)
政府的运作
政府资金来源:taxes(taxpayer)
政府资金去向:public services,如果政府对某些public service增加资金投入,那么对于其他的public service的投入必然相对来说会减少(financial burden)。
公民的权利与责任
权利:人权(human right),自由(freedom)
责任:保护环境(protect the environment),承担自己的行为带来的后果(bear the consequences of their own actions),纳税(pay the tax)
环境:引申出来的话题:
全球变暖
垃圾问题:
相关词汇积累:
- global warming, greenhouse effect,the imporper disposal of waste,non-degradable,air pollution,species,extinction
媒体新闻
媒体人责任
关注喜爱度
政治观点的宣传
工作
工资:用于满足基本生活的需要(meet basic needs)和过上有品质的生活(have a reasonable quality of life)
工作氛围和公司福利条件
工作的稳定性和后续职业的发展
工作的不可替代性
对于社会和国家的贡献
幸福
满足需求:物质层面 or 精神层面
健康的身体、家人朋友的陪伴、安全的住所、稳定的收入
大作文自己没有想到的表达
生态平衡:ecological balance
破坏生物多样性:destroy/ruin the biodiversity
在某种程度上:to an extend
碳酸饮料:carbonated beverage
论坛网站:forum site
体罚:corporal punishment
acquire informations: 获取信息
none other than = only
should be concentrated more
are provided with more opportunities = have opportunities
大作文自己需要注意的点
- 避免不相关的描述,回答问题+观点清晰,不要过度描写细节,如果某些内容可有可无,在不影响总字数的前提下,就删去
分句:一个句子只能有一个主语,如果要一句话有多个主语一定要用从句或者加上连接词
不要写缩写,例如were not不要写成weren’t,should not不要写成shouldn’t
如果优缺点有某个方面想不出来太多,可以用这样的表达:there are many good/bad impacts, and the most imperative one is xxx
- 不要随意的加人称代词,注意人称指代要写正确,主格宾格要写正确
不要写排比句,英文没有排比句,一定要加衔接词
to be blame 不要写出 to be blamed for
be taken with more notice
结尾段简单总和下自己的观点
不要写一些特别简单的表达,例如:good、can have
大作文审题总结
看题目说的是哪个层面的问题,一般分为三个层面:个人/社会/国家
看到个人要联想到的话题:
- 人权
- 个人性格养成
- 未来就业
看到社会要联想到的话题
就业
经济
社会价值观
公平
教育
贫富差距
稳定
环境
福利待遇
看到国家要联想到的话题
全球化
旅游业
民族凝聚力
国家形象
国际关系
常用的改写句型
被动句
强调句
双重否定句
倒装句
k8s常用命令
linux网络
路由
路由可以分为以下三种:
主机路由:表示到某台具体主机的路由(目前来说很少使用了)
网络路由:表达到某个网段的路由
默认路由:即
0.0.0.0/0对应的路由项,它用于在路由表中查不到匹配项时进行的默认路由
路由表不用记录同一网段中的其他主机的ip,同一网络中的主机通信直接通过数据链路层的ARP协议查询到IP地址对应的MAC地址后进行通信即可。
linux路由表组成部分
在linux中可以使用ip route命令来查看路由表。路由表项由以下几个部分组成:
destination:路由目标路径
interface:路由器的出口
gateway
直连情况(即两个ip之间没有通过路由器相连):不需要配置gateway,或者值为0.0.0.0
非直连情况:需要配置gateway,其值为下一个路由器在本网络中(当路由器对接多个网络时,会有多个网络地址)的ip地址
路由表配置
pod详解
pod是k8s集群中的最小调度单元,一个pod中可以有多个容器。k8s引入pod,而不直接对容器进行调度的原因有如下两个:
一个是为了将容器的实现和k8s平台自身引擎的实现进行解耦,从而做到可以支持多种类型的容器(docker、rkt)
另外一个是可以让多个容器共享网络、存储、进程空间,减少资源消耗
使用yaml定义一个pod
1 | apiVersion: v1 |
定义好一个pod描述之后,就可以使用kubectl create -f xxx.yaml来创建一个pod
pod的常用操作
查看pod被调度的节点已经pod ip
1
kubectl -n <namespace> get pod -o wide
查看pod的配置
1
kubectl -n <namespace> get pod <pod name> -o <yaml|json>
查看pod的信息及事件
1
kubectl -n <namespace> describe pod <pod name>
进入pod内的容器
1
kubectl -n <namespace> exec <pod name> -c <container name> -it /bin/bash
查看pod内容器日志,显示标准或者错误输出日志
1
kubectl -n <namespace> logs -f <pod name> -c <container name>
更新pod
1
kubectl apply -f <pod yaml file> # 更新pod是使用更新yaml文件的形式
删除pod
1
2kubectl delete -f <pod yaml file> # 根据配置文件删除
kubectl -n <namespace> delete pod <pod name> # 根据pod name删除
Pod健康检查
pod的健康检查由kubelet来进行,pod健康检查有两种机制:
LivenessProbe:存活性探测,用于判断容器是否存活,即pod是否为running状态。如果LivenessProbe探针探测到容器不健康,则kubelet将kill掉容器,并根据容器的重启策略是否重启(如果不配置,默认会进行重启),如果一个容器不包含LivenessProbe探针,则kubelet认为容器的LivenessProbe探针的返回值永远成功,即任务容器是健康的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16...
containers:
- name:
image:
livenessProbe:
httpGet: #有三种类型:exec(执行脚本,脚本返回0表示健康)、
#httpGet(返回200-399状态码表示健康)、
#tcpSocket(如果能够建立TCP连接,则表示健康)
path:
port:
scheme:
initialDelaySeconds: # 容器启动后多少秒后第一次执行探测
periodSeconds: # 多少秒执行一次探,默认10s,最小1s,
timeoutSeconds: # 探测超时时间默认1s,最小1
successThreshold: # 连续探测成功多少次才被认为是成功,默认为为1
failureThreshold: # 连续探测失败多少次才被任务是失败,默认为3ReadinessProbe:可用性探测,用于判断容器是否正常提供服务,即容器的Ready是否为True,是否可以接收请求。如果ReadinessProbe探测失败,则容器的ready将为False,Endpoint Controller控制器会将此Pod的Endpoint从对应的service的Endpoint列表中移除,不再将任何请求调度到此Pod上,直到下次探测成功。
1
2
3
4
5
6
7
8
9
10
11
12
13...
containers:
- name:
image:
readinessProbe:
httpGet:
path:
port:
scheme:
initialDelaySeconds: # 容器启动后多少秒后第一次执行探测
periodSeconds: # 多少秒执行一次探测
timeoutSeconds: # 探测超时时间
...
重启策略
Pod的重启策略应用于Pod内的所有容器,并且仅在Pod所处的Node上由Kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应的操作。Pod的重启策略包括Always、OnFailure和Never,默认值为Always。 * Always:当容器进程退出后,由kubelet自动重启该容器 * OnFailure:当容器进程终止运行且退出码不为0时,由kubelet自动重启该容器 * Never:不论容器运行状态如何,kubelet都不会重启该容器1 | ... |
1 | ... |
1 | ... |
1 | apiVersion: v1 |
1 | apiVersion: v1 |
1 | spec: |
1 | ... |
1 | apiVersion: apps/v1 |
1 | kubectl -n <namespace> scale deployment <deployment name> --replicas=<n> |
1 | kubectl -n <namespace> apply -f <xxx.yaml> |
1 | kubectl -n <namespace> set image deployment <deployment name> <container name>=<image> |
1 | kubectl -n <namespace> rollout history deployment <deployment name> |
1 | kubectl -n <namespace> rollout undo deployment <deployment name> --to-revision=<revsion number> |
1 | apiVersion: apps/v1 |
Service负载均衡之Cluster IP
通过deployment,我们已经可以创建一组Pod来提供具有高可用性的服务,虽然每个Pod都会分配一个单独的Pod IP, 然而却存在如下两个问题:
Pod IP仅仅是集群内部的虚拟IP,在集群内部可以访问,外部却无法访问
Pod IP会随着Pod的销毁而消失,当ReplicaSet对Pod进行动态伸缩容时,Pod IP可能随时会发生变化,这样对于我们访问这个服务带来了难度
Services是一组pod服务的抽象,相当于一组pod的load balancer,负责将请求分发到对应的pod。service会有一个IP,一般称为cluster ip,service对象通过selector进行标签选择,找到到对应的pod
使用yaml定义一个service
1 | apiVersion: v1 |
创建好service后,在集群内部就可以直接使用service name + port对服务进行访问,因为集群内部的dns会记录相关解析规则
Service负载均衡之NodePort
Cluster IP也是一个虚拟地址,其目的是为了方便集群内部服务直接的通信,只能在k8s集群内部进行访问,如果需要集群外部访问集群内部服务,实现方式之一为使用NodePort方式。NodePort会默认在30000—32767之间,不指定会随机使用其中的一个。
1 | apiVersion: v1 |
kube-proxy
kube-proxy运行在每个节点上,监听API Server中服务对象的变化,再通过创建流量路由规则来实现网络的转发。kube-proxy支持三种模式:
User space:让kube-proxy 在用户空间监听一个端口,所有的service都转发到这个端口,然后kube-proxy在内部应用层对其进行转发,所有报文都走一遍用户态,性能不高,在k8s v1.2版本后废弃
Iptables:当前默认模式,完全由iptables来实现,通过各个节点上的iptable规则来实现service的负载均衡,但是随着service数量增大,iptables模式由于线性查找匹配、全量更新等特点,其性能会显著下降
IPVS:与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。k8s 1.8版本开始引入,1.11版本开始稳定,需要开启宿主机的ipvs模块
Ingress
对于k8s的service,无论是Cluster-IP还是NodePort的形式,都是四层的负载,集群内的服务如果实现7层的负载均衡,这就需要借助与Ingress。Ingress控制器的实现方式有很多,例如nginx、contour、haproxy,trafik,istio。
ingress-nginx是7层的负载均衡器,根据用户编写的ingress规则(创建的Ingress的yaml文件),动态的去更改nginx服务的配置文件。
1 | apiVersion: networking.k8s.io/v1beta1 |
Ingress实现逻辑
Ingress controller通过api server,监听集群中Ingress规则变化
然后读取ingress规则(规则就是写明了哪个域名对应哪个service),按照自定义的规则,生成一段nginx配置
再写到nginx-ingress-contoller的pod里,nginx-ingress-controller的pod里运行着Nginx服务
Ingress 可以看作是在内部Service上做的一层反向代理
docker网络
网络模式
我们在使用docker run创建Docker容器时,可以用--net选项指定容器的网络模式,docker有以下4中网络模式:
bridage模式:docker容器默认的网络模式。它的原理类似交换机设备,而在linux中,能够起虚拟交互作用的,就是网桥(bridge)。它是一个工作在数据链路层的软件,主要功能是根据MAC地址将数据包转发到网桥的不同端口上。
有了网桥之后,容器在启动时,会执行如下操作:
创建一对虚拟接口/网卡,也就是veth pair
veth pair一端桥接到默认的名称为
docker0的网桥或者其他指定网桥上,并具有一个唯一的名字,如veth9953b75veth pair一端放到新启动的容器内部,并修改名字作为eth0
从虚拟网桥可用地址段中(也就是bridge对应的network)获取一个空闲地址分配给容器内的eth0
容器内部配置默认路由到网桥
如果容器内部需要访问外部网络,需要经过容器内部的eth0网卡、虚拟网桥、宿主机网卡最终访问到外网。如果容器内部需要访问其他容器网络,需要经过容器内部eth0网卡、虚拟网桥、其他容器内部etho0最终访问到其他容器。
host模式:容器内部不会创建网络命名空间(Network Namespace),容器共享宿主机的网络空间。
container模式:这个模式指定新创建的容器和已经存在的一个容器共享一个网络命名空间(Network Namespace)、网卡、ip。这种模式在一些特殊的场景中非常有用,例如k8s的pod,k8s为pod创建一个基础设施容器,该pod下的其他容器都以container模式共享这个技术设施容器的网络命名空间,相互之间以localhost访问,构成一个统一的整体。
none模式:只会在容器内创建网络命名空间(Network Namespace),不会创建虚拟网卡
docker 实现原理
Linux Namespace资源隔离
Linux命名空间是全局资源的一种抽象,将资源发到不同的命名空间中,各个命名空间中的资源时相互隔离的。命名空间有以下几种类别
| 分类 | 系统调用参数 | 相关内核版本 |
|---|---|---|
| Mount Namespace | CLONE_NEWNS | Linux 2.4.19 |
| UTS Namespace | CLONE_NEWUTS | Linux 2.6.19 |
| IPC Namespace | CLONE_NEWIPC | Linux 2.6.19 |
| PID Namespace | CLONE_NEWPID | Linux 2.6.24 |
| Network Namespace | CLONE_NEWNET | 始于Linux 2.6.24 完成于2.6.29 |
| User Namespace | CLONE_NEWUSER | 始于Linux2.6.23 完成于3.8 |
查看进程的namespace
1 | ls -l /proc/<pid>/ns |
CGroup资源限制
通过Namespace可以保证容器之间的隔离,但是无法控制容器可以占用多少资源,如果其中的某一个容器正在执行CPU计算密集型任务,那么就会影响其他容器任务的性能与执行效率,导致多个容器相互影响并且抢占资源。
CGroup(Control Group)就是能够隔离宿主机上的物理资源,例如CPU、内存、磁盘I/O和网络带宽。而我们需要做的就是把容器进程加入到指定的CGroup中。
UnionFS 联合文件系统
Linux Namespace和cgroup分别解决了容器的资源隔离与资源限制,那么容器是很轻量的,通常每台机器中可以运行几十上百个容器,这些容器可能会公用一个image。所以容器在启动的时候,不可能各自将这个image复制一份。Docker在内部使用镜像分层存储以及UnionFS来实现多个容器共用一个镜像。
镜像分层存储:docker镜像是由一系列的层组成的,每层代表Dockerfile中的一条指令,比如下面的Dockerfile文件:
1
2
3
4FROM ubuntu:15.04
COPY . /app
RUN make /app
CMD python /app/app.py这个dockerfile文件最终生成镜像的时候会生成四层,这四层是不可写的,而通过镜像实例化容器的过程,其实就是在就是在这四层之上添加了一个可写层,也就是我们通常说的容器层。而对容器层的操作,主要是利用了写时复制(CoW,copy on write)的技术。例如,如果当前操作会改变下面四层的某一层,docker会先将该层拷贝到容器层,然后再在容器层中进行操作。
UnionFS 其实是一种为Linux操作系统设计的,用于把多个文件系统联合到同一个挂载点的文件系统服务。
dft
类与接口
第37条:用组合起来的类来实现多层结构,不要用嵌套的内置类型
一般我们在编写项目代码时,由于初始的需求简单,需要用到的数据结构也简单,所以我们会经常使用python提供的容器来用做类的内部状态记录。但是随着需求的迭代,我们可能会使用到数据结构可能会更变得复杂,这时,我们不能简单的对用于记录内部状态的容器进行嵌套,而是应该考虑将内部的某些状态封装成一个类,并在外部的接口类中对这些数据类进行组合。
第38条:让简单的接口接受函数,而不是类的实例
Python有很多内置的API,都允许我们传入某个函数来定制它的行为,这种函数被成为hook函数,API在执行的时候,会调用这些hook函数。例如,list类的sort方法的key参数。在其他编程语音中,hook函数可能是通过抽象类或者接口来定义的(例如Java),但在python中一般是直接使用无状态的函数(即不会对内部状态进行修改)
第39条:通过@classmethod多态来构造同一体系中的各类对象
推导与生成
第27条:用列表推导取代map与filter
Python里面有一种很精简的写法,可以根据某个序列或可迭代对象派生出一份新的列表。用这种写法写成的表达式,叫作列表推导。假设我们要用列表中每个元素的平方值构建一份新的列表:
1 | a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
这种功能也可以使用内置函数map实现,它能够从多个列表中分别取出当前位置上的元素,并把它们当作参数传给映射函数,以求出新列表在这个位置上的元素值:
1 | alt = map(lambda x: x**2, a) |
列表推导还有一个地方比map好,就是它能够方便地过滤原列表,把某些输入值对应的计算结果从输出结果中排除。例如,假设新列表只需要纳入原列中那些偶数的平方值,那么我们可以在推导的时候再添加一个条件表达式:
1 | even_squares = [x**2 for x in a if x % 2 == 0] |
这种功能也可以通过内置的filter与map函数来实现,但是这两个函数相结合的写法要比列表推导难懂一些。
1 | alt = map(lambda x : x**2, filter(lambda x: x % 2 == 0, a)) |
上面这个写法是先用filter对a中的元素进行过滤形成新的列表,然后在对这个新的列表用map函数生成最终结果。
字典与集合也有相应的推导机制,分别叫做字典推导与集合推导,可以根据原字典与原集合创建新字典与新集合。1 | even_squares_dict = {x: x**2 for x in a if x % 2 == 0} |
如果改用map与filter实现,那么还必须调用相应的构造器(constructor),这会让代码变得很长,需要分成多行才能写得下。这样看起来比较乱,不如使用推导机制的代码清晰。
1 | alt_dict = dict(map(lambda x: (x, x**2), filter(lambda x: x % 2 == 0, a))) |
第28条:控制推导逻辑的子表达式不要超过两个
列表推导除了最基本的用法外,列表推导还支持多层循环。例如,要把二维列表转化为普通的一维列表,那么可以在推导时,使用两条for子表达式。这些子表达式会按照从左到右的顺序解读。
1 | matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
这样写简单易懂,也是多层循环在列表推导中的合理用法。多层循环还可以用来重制那种两层深的结构。例如,要根据二维矩阵里每个元素的平方值来构建一个新的二维矩阵:
1 | squared = [[x**2 for x in row] for row in matrix] |
如果推导过程中还要再加一层循环,那么语句就会变得很长,必须把它分成多行来写,例如下面是把一个三维矩阵转化成普通一维列表的代码:
1 | my_lists = [ |
1 | flat = [] |
推导的时候,可以使用多个if条件,如果这些if条件出现在同一层循环内,那么它们之间默认是and关系,也就是必须同时成立。例如,如果要用原列表中大于4且是偶数的值来构建新列表,那么既可以连用两个if,也可以只用一个if,下面两种写法效果相同:
1 | a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
在推导时,每一层的for子表达式都可以带有if条件。假如要根据原矩阵构建新的矩阵,把其中各元素之和大于等于10的那些行选出来,而且只保留其中能够被3整除的那些元素。这个逻辑用列表推导来写,并不需要太多的代码,但是这些代码理解起来会很困难:
1 | matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
1 | stock = { |
1 | result = {name: get_batches(stock.get(name, 0), 8) |
1 | result = {name: batches for name in order |
1 | result = {name: (tenth := count // 10) |
但是,如果把赋值表达式移动到if条件里面,就可以解决这个问题:
1 | result = {name: tenth for name, count in stock.items() |
第30条:不要让函数直接返回列表,应该让它逐个生成列表里面的值
如果函数要返回的是个包含许多结果的序列,那么最简单的办法就是把这些结果放到列表中。例如,我们要返回字符串里每个单词的首字母在字符串中所对应的下标:
1 | def index_words(text): |
上面的index_words函数也可以改用生成器来实现。生成器由包含yield表达式的函数创建。下面就定义一个生成器函数,实现与刚才那个函数相同的效果:
1 | def index_words_iter(the_text): |
1 | it = index_words_iter(the_text) |
如果确实要制作一份列表,那可以把生成器函数返回的迭代器传给内置的list函数:
1 | result = list(index_words_iter(the_text)) |
index_words_iter相对于index_words来说,不必一次性把所有结果都保存到列表中,在数据的数据较多的情况下,index_words有可能因为耗尽内存而导致程序崩溃。
使用这些生成器函数时,只有一个地方需要注意,就是调用者无法重复使用函数所返回的迭代器,因为迭代器是有状态的(参见第31条)。
第31条:谨慎地迭代函数所接受的可迭代参数
如果函数接受的参数是个可迭代对象,那么我们可能会在函数中对其迭代多次。例如,我们要分析美国德克萨斯州的游客数量。原始数据保存在一份列表中,其中的每个元素表示每年有多少游客(单位是百万)。我们要统计每个城市的游客数占游客总数的百分比。
1 | def normalize(numbers): |
在normalize函数中会对numbers参数进行两次迭代,一次是在sum函数的调用中,一次是在for循环中。
如果我们给nomalize函数传入参数的是一个列表,我们可以的得到正确的结果:
1 | visits = [15, 35, 80] |
但是如果我们传给nomalize函数的是个迭代器,例如在数据规模较大,需要从文件中读取数据时:
1 | def read_visits(data_path): |
奇怪的是,对read_visits所返回的迭代器调用normalize函数之后,并没有得到结果:
1 | it = read_visits('my_numbers.txt') |
出现这种状况的原因在于,迭代器只能进行一次迭代,并且迭代后不可重置。在sum函数中,已经对迭代器进行过一次迭代了,所以在for循环中由于没有数据可迭代,所以也就不会进行循环内部。
一种解决办法是让normalize函数接受另外一个函数,使它每次要使用迭代器时,都要向那个函数去索要:
1 | def normalize_func(get_iter): |
这么做虽然可行,但是每次调用normalize_func都需要传入一个函数,更好的方法是自定义一种容器类,并让其实现迭代器协议(iterator protocol)。
1 | class ReadVisits: |
1 | visits = ReadVisits(p[11.538, 26.924, 61.538]ath) |
1 | value = [len(x) for x in open('my_file.txt')] |
1 | it = (len(x) for x in open('my_file.txt')) |
生成器表达式还有个强大的特性,就是可以组合起来,例如,可以用刚才那条生成器表达式所形成的it迭代器作为输入,编写一条新的生成器表达式:
1 | roots = (x, x**0.5) for x in it) |
第33条:通过yield from把多个生成器连起来用
生成器(yield)有很多好处,能够解决很多常见的问题。生成器的用途很广,所以许多程序都会频繁使用它们,而且是一个连一个地用。
例如,我们要编写一个图形程序,让它在屏幕上面移动图像,从而形成动画效果。假设要实现这样一段动画:图片先快速移动一段时间,然后暂停,接下来慢速移动一段时间。我们用生成器来表示图片在当前时间段内应该保持的速度:
1 | def move(period, speed): |
为了把完整的动画制作出来,我们需要调用三次move:
1 | def animate(): |
上面这种写法的问题在于,animate函数里有很多重复的地方。比如它反复使用for结构来操作生成器,而且每个for结构都使用相同的yield表达式。为了解决这个问题,我们可以改用yield from形式的表达式来实现。这种形式,会先从嵌套进去的小生成器里面取值,如果该生成器已经用完,那么程序的控制流程就会回到yield from所在的这个函数之中:
1 | def animate(): |
上面使用yield from的代码看上去更清晰、更直观,并且这种实现方式的运行效率要更快。
第34条:不要用send给生成器注入数据
第35条:不要通过throw变换生成器的状态
说实话,第34条和第35条没怎么看懂,第一主要是生成器的这两个高级特性使用的场景也并不多,第二是感觉作者的代码示例也不太贴合实际场景中会写的代码。第36条:考虑用itertools处理迭代器与生成器
Python内置的itertools模块中有很多函数,可以用来对迭代器进行一些高级处理。下面分三大类,列出其中最重要的函数。
连接多个迭代器
chain: 可以把多个迭代器从头连接到尾形成一个新的迭代器1
2
3
4
5
6
7it1 = iter([1, 2, 3])
it2 = iter([4, 5, 6])
it3 = itertools.chain(it1, it2)
print(list(it))
>>>
[1, 2, 3, 4, 5, 6]repeat: 可以制作这样的一个迭代器,它会不停得输出某个值,或者通过第二个参数来控制最多能输出几次1
2
3
4
5it = itertools.repeat('hello', 3)
print(list(it))
>>>
['hello', 'hello', 'hello']cycle: 可以制作这样的一个迭代器,它会循环地输出某段内容之中的各个元素1
2
3
4
5
6it = itertools.cycle([1, 2])
result = [next(it) for _ in range(5)]
print(result)
>>>
[1, 2, 1, 2, 1]tee: 可以让一个迭代器分裂成多个平行迭代器,具体个数由第二个参数指定。如果这些迭代器推进的速度不一样,那么程序可能要用大量内存做缓存,以存放进度落后的迭代器会用到的元素。1
2
3
4
5
6
7
8
9it1, it2, it3 = itertools.tee([1, 2, 3], 3)
print(list(it1))
print(list(it2))
print(list(it3))
>>>
[1, 2, 3]
[1, 2, 3]
[1, 2, 3]zip_longest: 它与内置的zip函数类似(参见第8条),但区别是,如果源迭代器的长度不同,那么它会用fillvalue参数的值来填补提前耗尽的那些迭代器所留下的空缺。1
2
3
4
5
6
7
8
9
10
11
12keys = ['one', 'two', 'three']
values = [1, 2]
normal = zip(keys, values)
print('zip:', list(normal))
it = itertools.zip_longest(key, values, fillvalue='nope')
print('zip_longest:', list(it))
>>>
zip: [('one', 1), ('two', 2)]
zip_longest: [('one', 1), ('two', 2), ('three', 'nope')]
过滤迭代器中的元素
islice: 可以在不拷贝数据的前提下,按照下标切割源迭代器,这种切割方式与标准的序列切片以及步进机制类似1
2
3
4
5
6
7
8
9
10it = iter([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
first_five = itertools.islice(it, 5)
print('First Five:', list(first_five))
middle_odds = itertools.islice(it, 2, 8, 2)
print('Middle odds:', list(middle_odds))
>>>
First five: [1, 2, 3, 4, 5]
Middle odds: [3, 5, 7]takewhile: 会一值从源迭代器里获取元素,直到某元素让测试函数返回False为止:1
2
3
4
5
6it1 = iter([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
it2 = itertools.takewhile(lambda x: x < 7, it1)
print(list(it2))
>>>
[1, 2, 3, 4, 5, 6]dropwhile: 与takewhile相反,dropwhile会一直跳过源序列里的元素,直到某元素让测试函数返回True为止,然后它会从这个地方开始逐个取值1
2
3
4
5
6it1 = iter([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
it2 = itertools.dropwhile(lambda x: x < 7, it1)
print(list(it2))
>>>
[7, 8, 9, 10]filterfalse: 和内置的filter函数相反,它会逐个输出源迭代器里使得测试函数返回False的那些元素1
2
3
4
5
6
7
8
9
10
11
12it = iter([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
evens = lambda x : x % 2 == 0
filter_result = filter(evens, it)
print('Filter:', list(filter_result))
filter_false_result = itertools.filterfalse(evens, it)
print('Filter false:', list(filter_false_result))
>>>
Filter: [2, 4, 6, 8, 10]
Filter false: [1, 3, 5, 7, 9]
用源迭代器中的元素合成新元素
accumulate: accumulate 会从源代码迭代器取出一个元素,并把已经累计的结果与这个元素一起传给表示累加逻辑的函数,然后输出那个函数的计算结果,并把结果当成新的累计值。这与内置的functools模块中的reduce函数,实际上是一样的,只不过这个函数每次只给出一项累加值。如果调用者没有指定表示累加逻辑的函数,那么默认的逻辑就是两值相加。1
2
3
4
5
6
7
8
9
10
11
12it = iter([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
sum_reduce = itertools.accumulate(it)
print('Sum:', list(sum_reduct))
def sum_modulo_20(first, second):
output = first + second
return output % 20
modulo_reduce = itertools.accumulate(it, sum_modulo_20)
print('Modulo:' list(module_reduce))
>>>
Sum: [1, 3, 6, 10, ]product: 会从一个或多个源迭代器里获取元素,并计算笛卡尔积,1
2
3
4
5
6
7
8
9single = itertools.product([1, 2], repeat=2)
print('Single:', list(single))
multiple = itertools.product([1, 2], ['a', 'b'])
print('Multiple:', list(multiple))
>>>
Single: [(1, 1), (1, 2), (2, 1), (2, 2)]
Multiple: [(1, '1'), (1, 'b'), (2, 'a'), (2, 'b')]product: 会从源迭代器中能给出的全部元素,并逐个输出由其中N个元素组成的有序排列1
2
3
4
5it = itertools.permutations([1, 2, 3], 2)
print(list(it))
>>>
[(1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 2)]combinations: 会从源迭代器中能给出的全部元素,并逐个输出由其中N个元素组成的无序组合1
2
3
4
5it = itertools.combinations([1, 2, 3], 2)
print(list(it))
>>>
[(1, 2), (1, 3), (2, 3)]combinations_with_replacement: 和combination类似,但是它允许同一个元素在组合里多次出现:1
2
3
4it = itertools.combinations_with_replacement([1, 2, 3], 2)
print(list(it))
>>>
[(1, 1), (1, 2), (1, 3), (2, 2) (2, 3), (3, 3)]
数据复制
复制主要指通过互联网络在多台机器上保存相同数据的副本,通过数据复制方案,人们通常希望达到以下目的:
使数据在地理位置上更接近用户,从而降低访问延迟
当部分组件出现故障,系统依然可以继续工作,从而提高可用性
扩展至多台机器以同时提供数据访问服务,从而提高吞吐量
本章讨论的内容都是在假设数据规模比较小,集群的每一台机器都可以保存数据集的完整副本。在接下来的第6章中,我们讨论单台机器无法容纳整个数据集的情况(即必须分区)。在后面的章节中,我们还将讨论复制过程中可能出现的各种故障,以及该如何处理这些故障。
如果复制的数据一成不变,那么复制就非常容易:只需将数据复制到每个节点,一次即可搞定。然而所有的技术挑战都在于处理那些持续更改的数据,而这正是本章讨论的核心。我们将讨论是三种流行的复制变化数据的方法:主从复制、多节点复制和无主节点复制。几乎所有的分布式数据库都使用上述方法中的某一种,而三种方法各有优缺点。
主从复制
每个保存数据库完整数据集的节点称之为副本。当有了多个副本,不可避免地会引入一些问题:如何确保所有副本之间的数据是一致的?
对于每一笔数据写入,所有副本都需要随之更新,否则,某些副本将出现不一致。最常见的解决方案是基于主节点的复制,也即主从复制。主从复制的工作原理如下:
指定某一个副本为主副本(或主节点)。当客户写数据库时,必须将写请求发送给主副本,主副本首先将数据写入本地存储。
其他副本则全称为从副本(或从节点)。主副本把数据写入本地存储后,将数据更改为复制的日志或更改流发送给所有从副本。每个从副本获得更改日志后将其应用到本地,且严格保持与主副本相同的写入顺序。
客户端从数据库中读数据时,既可以在主副本也可以在从副本上执行查询。
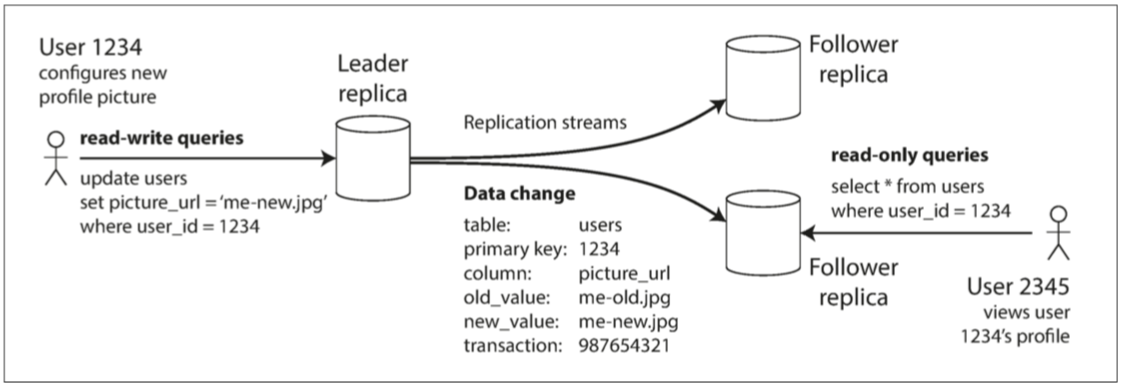
许多关系型数据库都内置支持主从复制,例如PostgresSQL、Mysql、SQL Server。一些非关系型数据库如MongoDB、RethinkDB和Espresso也支持主从复制。另外,主从复制技术也不仅限于数据库,还广泛应用于分布式消息队列如Kafka和RabbitMQ,以及一些网络文件系统和复制块设备(如DRBD)
同步复制与异步复制
复制非常重要的一个设计选项是同步复制还是异步复制。对于关系数据库系统,同步或异步通常是一个可配置的选项;而其他系统则可能是硬性指定或者只能二选一。
结合一个例子,假设网站用户需要更新首页的头像图片。其基本流程是,客户将更新请求发送给主节点,主节点接收到请求,接下来将数据更新转发给从节点。最后,由主节点来通知客户端更新完成。
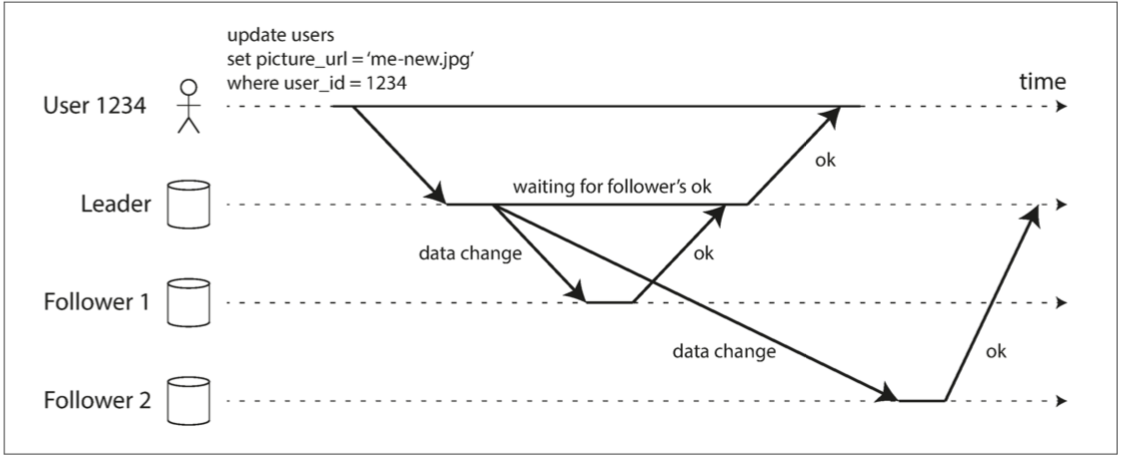
在上图中,从节点1的复制是同步的,即主节点需等待直到从节点1确认完成了写入,然后才会向用户报告完成,并且将最新的写入对其他客户端可见。而从节点2的复制是异步的:主节点发送完消息之后立即返回,不用等待从节点2完成确认。
从节点2在接收到复制日志并完成数据同步有一段延迟,通常情况下,复制速度会非常快,例如多数数据库系统可以在一秒之内完成所有从节点的更新,但是,系统其实并没有保证一定会在多长时间内完成复制。有些情况下,从节点可能落后主节点几分钟甚至更长时间,例如,由于从节点刚从故障中恢复,或者系统已经接近最大设计上限,或者节点之间的网络出现问题。
同步复制的优点是,一旦向用户确认,从节点可以明确保证完成了与主节点的更新同步,数据已经处于最新版本。万一主节点发生故障,总是可以在从节点继续访问最新数据。缺点则是,如果同步的从节点无法完成确认(例如由于从节点发生崩溃,或者网络故障,或任何其他原因),写入就不能视为成功。节点会阻塞所有的写操作,直到同步副本确认完成。
因此,把所有的节点都配置为同步复制有些不切实际。因为这样的话,任何一个同步节点的中断都会导致整个系统更新停滞不前。实践中,如果数据库启用了同步复制,通常意味着其中某一个从节点是同步的,而其他节点则是异步模式。万一同步的从节点变得不可用或性能下降,则将另一个异步的从节点提升为同步模型。这样可以保证至少有两个节点(即主节点和一个同步从节点)拥有最新的数据副本。这种配置有时也称为半同步。
主从复制还经常会被配置为全异步模式。此时如果主节点发送失败且不可恢复,则所有尚未复制到从节点的写请求都会丢失。这意味着即使向客户端确认了写操作,却无法保证数据一定会持久化存储到。但全异步配置的优点则是,不管从节点上数据多么滞后,主节点总是可以继续响应写请求,系统的吞吐性能更好。
全异步模式这种弱化的持久性听起来是一个非常不靠谱的折中设计,但是异步复制还是被广泛使用,特别是那些从节点数量巨大或者分布于广域地理环境。
配置新的从节点
如果出现一下情况时,如需要增加副本数以提高容错能力,或者替换失败的副本,就需要考虑增加新的从节点,但如何确保新的从节点和主节点保持数据一致呢?
简单地将数据文件从一个节点复制到另一个节点通常是不够的,主要是因为客户端仍在不断向数据库写入新数据,数据始终处于不断变化之中,因此常规的文件拷贝方式将会导致不同节点上呈现不同时间点的数据,这不是我们所期待的。
或许应该考虑锁定数据库(使其不可写)来使磁盘上的文件保持一致,但这会违反高可用的设计目标,好在我们可以做到不停机、数据服务不中断的前提下完成从节点的设置。逻辑上的主要操作步骤如下:
- 在某个时间点对主节点的数据副本产生一个一致性快照,这样避免长时间锁定整个数据库。
- 将此快照拷贝到新的从节点
- 从节点连接到主节点请求快照点所发生的数据更改日志。因为在第一步创建快照时,快照与系统复制日志的某个确定位置相关联。
- 获取日志之后,从节点来应用这些快照点之后所有数据变更,这个步骤称之为追赶。
建立新的从副本具体操作步骤可能因数据库系统而异,某些系统中,这个过程是全自动化的,而在某些系统中由于所设计的步骤、流程可能会比较复杂,甚至需要管理员手动介入。
处理节点失效
系统中的任何节点都可能因故障或者计划内的维护(例如重启节点以安装内核安全补丁)而导致中断甚至停机。如果能够在不停机的情况下重启某个节点,这会对运维带来巨大的便利。我们的目标是,尽管个别节点会出现中断,但要保持系统总体的持续运行,并尽可能减小节点中断带来的影响。
从节点失效:追赶式恢复
根据副本的复制日志,从节点可以知道在发生故障之前所处理的最后一笔事务,然后连接到主节点,并请求自那笔事务之后中断期间内所有的数据变更。在收到这些数据变更日志之后,将其应用到本地来追赶主节点。之后就和正常情况一样持续接收来自主节点数据流的变化。
主节点失效:节点切换
处理主节点故障的情况则比较棘手:需要选择某个从节点将其提升为主节点,这一过程称之为切换。故障切换可以手动进行,例如通知管理员主节点发生失效,采取必要的步骤来创建新的主节点,或者以自动方式进行。自动切换的步骤通常如下:
确认主节点失效。大多数系统都采用了基于超时的机制:节点间频繁地互相发生发送心跳存活消息,如果发现某一个节点在一段比较长时间内(例如30s) 没有响应,即认为该节点发生失效。
选举新的主节点。可以通过选举的方式(超过多数的节点达成共识)来选举新的主节点,或者由之前选定的某控制节点来指定新的主节点。候选节点最好与原主节点的数据差异最小,这样可以最小化数据丢失的风险。
重新配置系统使新主节点生效,现在需要将写请求发送给新的主节点,如果原主节点之后重新上线,可能仍然自认为是主节点,而没有意识到其他节点已经达成共识迫使其下台。这时系统要确保原主节点降级为从节点,并认可新的主节点。
然而,上述切换过程依然充满了很多变数:
如果使用了异步复制,且失效之前,新的主节点并未收到原主节点的所有数据;在选举之后,原主节点很快又重新上线并加入到集群,新的主节点很可能会收到冲突的写请求,这是因为原主节点未意识的角色变化,还会尝试同步其他从节点,但其中的一个现在已经接管成为现任主节点。常见的解决方案是,原主节点上未完成复制的写请求就此丢弃,但这可能会违背数据更新持久化的承诺
在某些故障情况下,可能会发生两个节点同时都自认为是主节点。这种情况被称为脑裂,它非常危险:两个主节点都可能接受写请求,并且没有很好解决冲突的办法,最后数据可能会丢失或者破坏。作为一种安全应急方案,有些系统会采取措施来强制关闭其中一个节点
坦白讲,对于这些问题没有简单的解决方案。因此,即使系统可能支持自动故障切
换,有些运维团队仍然更愿意以手动方式来控制整个切换过程。上述这些问题,包括节点失效、网络不可靠、副本一致性、持久性、可用性与延迟之间各种细微的权衡,实际上正是分布式系统核心的基本问题
复制日志的实现
基于语句的复制
最简单的情况,主节点记录所执行的每个写请求(操作语句)并将该操作语句作为日志志发送给从节点。对于关系数据库,这意味着每个INSERT、UPDATE或DELEH语句都会转发给从节点,并且每个从节点都会分析并执行这些SQL语句,如同它们是来自客户端那样。
听起来很合理也不复杂,但这种复制方式有一些不适用的场景:
任何调用非确定性函数的语句,如NOW ()获取当前时间,或RAND ()获取一个随机
数等,可能会在不同的副本上产生不同的值
如果语句中使用了自增列,或者依赖于现有数据
有可能采取一些特殊措施来解决这些问题,但这里面存在太多边界条件需要考虑,因此目前通常首选的是其他复制实现方案。
基于预写日志(WAL)的复制
从节点收到日志进行处理,建立和主节点内容完全相同的数据副本。其主要缺点是日志描述的数据结果非常底层:一个WAL包含了哪些磁盘块的哪些字节发生改变,诸如此类的细节。这使得复制方案和存储引擎紧密耦合。如果数据库的存储格式从一个版本改为另一个版本,那么系统通常无法支持主从节点上运行不同版本的软件。
基于行的逻辑日志复制
另一种方法是复制和存储引擎采用不同的日志格式,这样复制与存储逻辑剥离。这种
复制日志称为逻辑日志,以区分物理存储引擎的数据表示。
关系数据库的逻辑日志通常是指一系列记录来描述数据表行级别的写请求:
对于行插入,日志包含所有相关列的新值
对于行刪除,日志里有足够的信息来唯一标识已删除的行,通常是靠主键,但如
果表上没有定义主键,就需要记录所有列的旧值
对于行更新,日志包含足够的信息来唯一标识更新的行,以及所有列的新值(或
至少包含所有已更新列的新值)
如果一条事务涉及多行的修改,则会产生多个这样的日志记录,并在后面跟着一条记
录,指出该事务已经提交。MySQL的二进制日志binlog (当配置为基于行的复制时)
使用该方式。
由于逻辑日志与存储引擎逻辑解耦,因此可以更容易地保持向后兼容,从而使主从节
点能够运行不同版本的软件甚至是不同的存储引擎。
基于触发器的复制
到目前为止所描述的复制方法都是由数据库系统来实现的,不涉及任何应用程序代码。通常这是大家所渴望的,不过,在某些情况下,我们可能需要更高的灵活性。例如,只想复制数据的一部分,或者想从一种数据库复制到另一种数据库,则需要将复制控制交给应用程序层。
触发器支持注册自己的应用层代码,使得当数据库系统发生数据更改(写事务)时自动执行上述自定义代码。
复制滞后问题
不幸的是,如果一个应用正好从一个异步的从节点读取数据,而该副本落后于主节点,则应用可能会读到过期的信息。这种不一致只是一个暂时的状态,如果停止写数据库,经过一
段时间之后,从节点最终会赶上并与主节点保持一致。这种效应也被称为最终一致性。
正常情况下,主节点和从节点上完成写操作之间的时间延迟(复制滞后)可能不足1秒,这样的滞后,在实践中通常不会导致太大影响。但是,如果系统已接近设计上限,或者网络存在问题,则滞后可能轻松增加到几秒甚至几分钟不等。当滞后时间太长时,导致的不一致性不仅仅是一个理论存在的问题,而是个实实在在的现实问题。
读自己的写
许多应用让用户提交一些数据,接下来査看他们自己所提交的内容,提交新数据须发送到主节点,但是当用户读取数据时,数据可能来自从节点。然而对于异步复制存在这样一个问题,用户在写入不久即查看数据,则新数据可能尚未到达从节点。对用户来讲,看起来似乎是刚刚提交的数据丢失了。对于这种情况,我们需要写后读一致性,机制保证如果用户重新加载页面,他们总能看到自己最近提交的更新。但对其他用户则没有任何保证,这些用户的更新可能会在稍后才能刷新看到。
基于主从复制的系统该如何实现写后读一致性呢?有多种可行的方案,以下例举一二:
- 如果用户访问可能会被自己修改的内容,从主节点读取;否则,在从节点读取。这背后就要求有一些方法在实际执行查询之前,就已经知道内容是否可能会被用户自己修改。例如,社交网络上的用户首页信息通常只能由所有者编辑,而其他人无法编辑。因此,这就形成一个简单的规则:总是从主节点读取用户自己的首页配置文件,而在从节点读取其他用户的配置文件。
单调读
如果用户从不同副本进行了多次读取,则很有可能出现一下情况:第一次查询返回了比较新的结果,但第二次查询时,由于副本滞后较多,返回给用户的数据相对于第一次变少了,对于用户来说感知到的情况就是数据被删除了。
单调读一致性可以确保不会发生这种异常,这是一个比强一致性弱,比最终一致性强的保证。当读取数据时,单调读一致性保证,如果某个用户依次进行多次读取,则他绝不会看到回滚现象,即在读取较新值之后又发生读旧值的情况。
实现单调读的一种方式是,确保每个用户总是从固定的冋一副本执行读取(而不同的用户可以从不同的副本读取)。例如,基于用户ID的哈希的方法而不是随机选择副本。但如果该副本发生失效,则用户的査询必须重新路由到另一个副本。
前缀一致读
在多人聊天的场景下,人与人之间聊天的顺序对于用户来说是很重要的,但是由于复制滞后的问题,用户可能会先收到其他用户在时间上相对后发出的消息,导致产生逻辑混乱。
防止这种异常需要引入另一种保证:前缀一致读。该保证是说,对于一系列按照某个顺序发生的写请求,那么读取这些内容时也会按照当时写入的顺序。
这是分区(分片)数据库中出现的一个特殊问题,细节将在第6章中讨论。如果数据库总是以相同的顺序写入,则读取总是看到一致的序列,不会发生这种反常。然而,在许多分布式据库中,不同的分区独立运行(异地多活),因此不存在全局写入顺序。这就导致当用户从数据库中读数据时,可能会看到数据库的某部分旧值和另一部分新值。
一个解决方案是确保任何具有因果顺序关系的写入都交给一个分区来完成,但该方案真实实现效率会大打折扣。现在有一些新的算法来显式地追踪事件因果关系。
复制滞后的解决方案
使用最终一致性系统时,最好事先就思考这样的问题:如果复制延迟增加到几分钟甚至几小时,那么应用层的行为会是什么样子?如果答案是“没问题”,那没得说。但是,如果带来糟糕的用户体验,那么在设计系统时,就要考虑提供一个更强的一致性保证,比如写后读。
正如前面所讨论的,在应用层可以提供比底层数据库更强有力的保证。例如只在主节点上进行特定类型的读取,而代价则是,应用层代码中处理这些问题通常会非常复杂,且容易出错。
如果应用程序开发人员不必担心这么多底层的复制问题,而是假定数据库在“做正确的情”,情况就变得很简单。而这也是事务存在的原因,事务是数据库提供更强保证的一种方式。
单节点上支持事务已经非常成熟。然而,在转向分布式数据库(即支持复制和分区)的过程中,有许多系统却选择放弃支持事务,并声称事务在性能与可用性方面代价过髙。后面的章节将会更深入的理解事务。
多主节点复制
主从复制存在一个明显的缺点:系统只有一个主节点,而所有写入都必须经由主节点。如果由于某种原因,例如与主节点之间的网络中断而导致主节点无法连接,主从复制方案就会影响所有的写入操作。
对主从复制模型进行自然的扩展,则可以配置多个主节点,每个主节点都可以接受写操作,处理写的每个主节点都必须将该数据更改转发到所有其他节点。这就是多主节点复制。此时,每个主节点还同时扮演其他主节点的从节点。
适用场景
在一个数据中心内部使用多主节点基本没有太大意义,其复杂性已经超过所能带來的好处。但是,在以下场景这种配置则是合理的:
数据中心
为了容忍整个数据中心级别故障或者更接近用户,可以把数据库的副本横跨多个数据中心。而如果使用常规的基于主从的复制模型,主节点势必只能放在其中的某一个数据中心,而所有写请求都必须经过该数据中心。有了多主节点复制模型,则可以在每个数据中心都配置主节点,在毎个数据中心内,采用常规的主从复制方案;而在数据中心之间,由各个数据中心的主节点来负责同其他数据中心的主节点进行数据的交换、更新。
有些数据库已内嵌支持了多主复制,但有些则借助外部工具来实现,例如MySQL的
Tungsten Replicator,PostgreSQL的BDR以及Oracle的GoldenGate,由于多主复制在许多数据库中还只是新增的髙级功能,所以可能存在配置方面的细小缺陷,在与其他数据库功能(例如自增主键,触发器和完整性约束等)交互时有时会出现意想不到的副作用。出于这个原因,一些人认为多主复制比较危险,应该谨慎使用或者避免使用。
离线客户端操作
比如手机,笔记本电脑和其他设备上的日历应用程序。无论设备当前是否联网,都需要能够随时査看当前的会议安排(对应于读请求)或者添加新的会议(对应于写请求)。在离线状态下进行的任何更改,会在下次设备上线时,与服务器以及其他设备同步。
这种情况下,毎个设备都有一个充当主节点的本地数据库(用来接受写请求),然后在所有设备之间采用异步方式同步这些多主节点上的副本,同步滞后可能是几小时或者数天,具体时间取决于设备何时可以再次联网。
从架构层面来看,上述设置基本上等同于数据中心之间的多主复制,只不过是个极端情况,即一个设备就是数据中心,而且它们之间的网络连接非常不可靠。有一些工具可以使多主配置更为容易,如CouchDB就是为这种操作模式而设计的。
协作编辑
实时协作编辑应用程序允许多个用户同时编辑文档。我们通常不会将协作编辑完全等价于数据库复制问题,但二者确实有很多相似之处。当一个用户编辑文档时,所做的更改会立即应用到本地(本地主节点),然后异步复制到服务器以及编辑同一文档的其他用户。
如果要确保不会发生编辑冲突,则应用程序必须先将文档锁定,然后才能对其进行编辑。如果另一个用户想要编辑同一个文档,首先必须等到第一个用户提交修改并释放锁。这种协作模式相当于主从复制模型下在主节点上执行事务操作
处理写冲突
多主复制的最大问题是可能发生写冲突,这意味着必须有方案来解决冲突。例如,两个用户同时编辑文档,用户1将页面的标题从A更改为B , 与此同时用户2却将标题从A改为C。每个用户的更改都顺利地提交到本地主节点。但是,当更改被异步复制到对方时,却发现存在冲突。
同步于异步冲突检测
如果是主从复制数据库,第二个写请求要么会被阻塞直到第一个写完成,要么被中止(用户必须重试),然而在多主节点的复制模型下,这两个写请求都是成功的,并且只能在稍后的时间点上才能异步检测到冲突,那时再要求用户层来解决冲突为时已晚。
理论上,也可以做到同步冲突检测,即等待写请求完成对所有副本的同步,然后再通知用户写入成功。但是,这样做将会失去多主节点的主要优势:允许每个主节点独立接受写请求。如果确实想要同步方式冲突检测,或许应该考虑采用单主节点的主从复制模型。
避免冲突
处理冲突最理想的策略是避免发生冲突,即如果应用层可以保证对特定记录的写请求总是通过同一个主节点,这样就不会发生写冲突。现实中,由于不少多主节点复制模型所实现的冲突解决方案存在瑕疵,因此,避免冲突反而成为大家普遍推荐的首选方案。
例如,多人协作文档系统中,对同一文档的写操作都在一个数据中心的主节点上,不同文档的写操作可以放在不同数据中心。从用户的角度来看,这基本等价于主从复制模型。
但是,有时可能需要改变事先指定的主节点,例如由于该数据中心发生故障,不得不将流量重新路由到其他数据中心。
收敛于一致状态
对于主从复制模型,数据更新符合顺序性原则,即如果同一个字段有多个更新,则最后一个写操作将决定该字段的最终值。
对于多主节点复制模型,由于不存在这样的写入顺序,所以最终值也会变得不确定。例如上面同步编辑文档的例子,主节点1接受到请求把标题更新为B , 然后更新为C ;而在主节点2,则是相反的更新顺序。两者都无法辩驳谁更正确。
如果每个副本都只是按照它所看到写入的顺序执行,那么数据库最终将处干不一致状态这绝对是不可接受的,所有的复制模型至少应该确保数据在所有副本中最终状态一定是一致的。因此,数据库必须以一种收敛趋同的方式来解决冲突,这也意味着当所有更改最终被复制、同步之后,所有副本的最终值是相同的。(可以理解为多主节点复制的最终一致性?)
实现收敛的冲突解决有以下可能的方式:
给每个写入分配唯一的ID, 例如,一个时间戳,一个足够长的随机数,一个UUID或者一个基于键-值的哈希,挑选最高ID的写入作为胜利者,并将其他写入丢弃。如果基于时间戳,这种技术被称为最后写入者获胜。虽然这种方法很流行,但是很容易造成数据丢失。我们将在后面详细解释。
为每个副本分配一个唯一的ID,并制定规则,例如序号髙的副本写入始终优先于序号低的副本。这种方法也可能会导致数据丢失
以某种方式将这些值合并在一起。例如,按字母顺序排序,然后拼接在一起,例如上面文档标题编辑的例子合并后的结果可能变成:BC
利用预定义好的格式来记录和保留冲突相关的所有信息,然后依靠应用层的逻辑,事后解决冲突(可能会提示用户)
自定义冲突解决逻辑
解决冲突最合适的方式可能还是依靠应用层,所以大多数多主节点复制模型都有工具来让用户编写应用代码来解决冲突。可以在写入时或在读取时执行这些代码逻辑:
在写入时执行
只要数据库系统在复制变更日志时检测到冲突,就会调用应用层的冲突处理程
序。例如,Bucardo支持编写一段Perl代码。这个处理程序通常不能在线提示用
户,而只能在后台运行,这样速度更快
在读取时执行
当检测到冲突时,所有冲突写入值都会暂时保存下来。下一次读取数据时,会将
数据的多个版本读返回给应用层。应用层可能会提示用户或自动解决冲突,并将
最后的结果返回到数据库。CouchDB采用了这样的处理方式。
自动冲突解决
冲突解决的规则可能会变得越来越复杂,且自定义代码很容易出错,有一些有意思的研究尝试自动解决并发修改所引起的冲突:
无冲突的复制数据类型 (Conflict**-**freeReplicated Datatypes,CRDT)。CRDT是可以由多个用户同时编辑的数据结构,包括map、ordered list、计数器等,并且以内置的合理方式自动地解决冲突
可合并的持久数据结构(Mergeable persistent data) 。它跟踪变更历史,类似于Git版本控制系统,并提出三向合并功能。
操作转换 (Operational transformation) 。它是Etherpad和Google Docs等协作编辑应用背后的冲突解决算法。专为可同时编辑的有序列表而设计,如文本文档的字符列表。
这些算法总体来讲还处于早期阶段,但将来它们可能会被整合到更多的数据系统中。这些自动冲突解决方案可以使主复制模型更简单、更容易被应用程序来集成。
拓扑结构
复制的拓扑结构描述了写请求从一个节点的传播到其他节点的通信路径。如果有两个主节点,则只存在一个合理的拓扑结构:主节点1必须把所有的写同步到主节点2,反之亦然。但如果存在两个以上的主节点,则会有多个可能的同步拓扑结构。