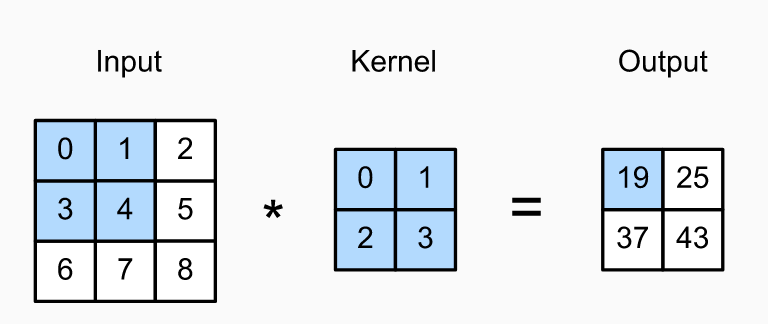
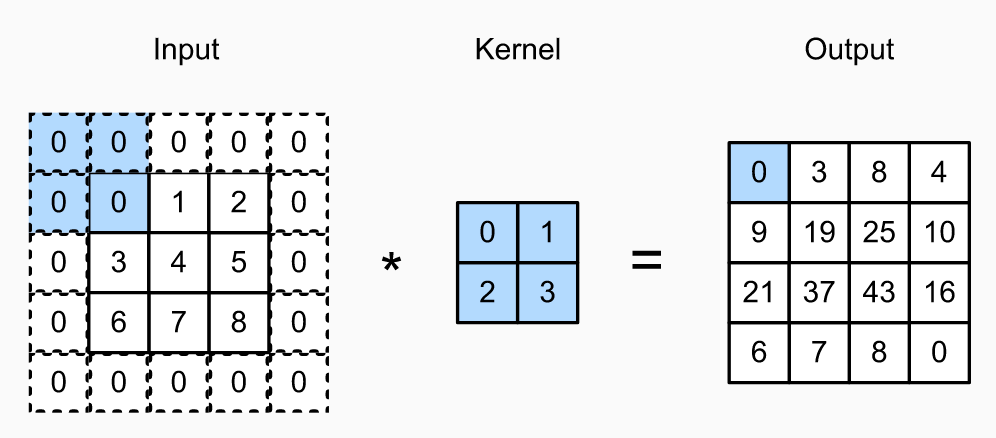
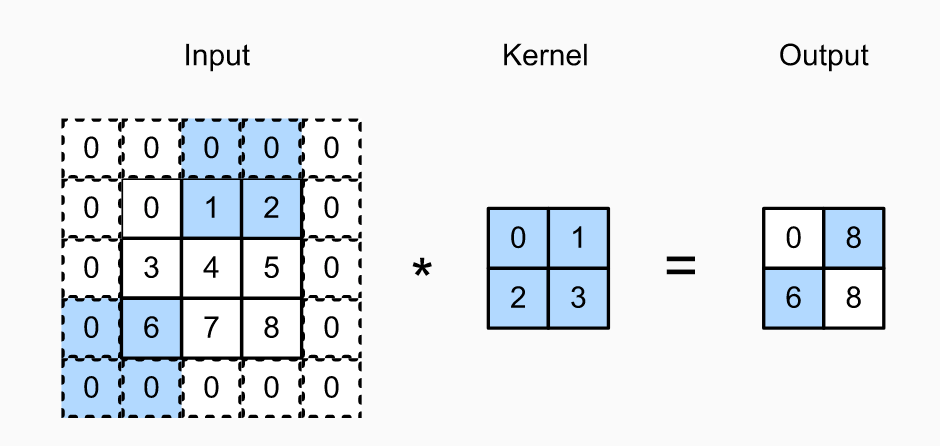
coin-or 简介
single: compile single lib by using configure
./configure \
—host=arm-apple-darwin \
—enable-static \
—disable-shared \
—prefix=$PWD/build/arm64 \
CC=gcc \
CFLAGS=”-DNDEBUG -miphoneos-version-min=8.0 -arch arm64 -g -O0 -fembed-bitcode \
-isysroot /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk” \
CXX=g++ \
CXXFLAGS=”-DNDEBUG -miphoneos-version-min=8.0 -arch arm64 -g -O0 -fembed-bitcode \
-isysroot /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk \
-std=c++11 -stdlib=libc++” \
LDFLAGS=”” \
LIBS=”-lc++ -lc++abi”
导出 PKG_CONFIG_PATH
export pkgconfig path
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/Users/bytedance/Desktop/coin-or/Osi/build/arm64/lib/pkgconfig
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/Users/bytedance/Desktop/coin-or/CoinUtils/build/arm64/lib/pkgconfig
pkgconfig folder can be read by pkg-config
遇到报错ld: -bind_at_load and -bitcode_bundle (Xcode setting ENABLE_BITCODE=YES) cannot be used together
export MACOSX_DEPLOYMENT_TARGET=”10.15.0”
ios
./coinbrew build Clp \
—host=arm-apple-darwin \
—enable-static \
—disable-shared \
—prefix=$PWD/ios \
CC=gcc \
CFLAGS=”-DNDEBUG -miphoneos-version-min=8.0 -arch arm64 -g -O0 -fembed-bitcode \
-isysroot /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk” \
CXX=g++ \
CXXFLAGS=”-DNDEBUG -miphoneos-version-min=8.0 -arch arm64 -g -O0 -fembed-bitcode \
-isysroot /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk \
-std=c++11 -stdlib=libc++” \
LDFLAGS=”” \
LIBS=”-lc++ -lc++abi” \
—tests none \
—no-third-party \
—verbosity 4
osx to_be_fixed
./coinbrew build Clp —enable-static —disable-shared CC=clang CXX=clang++ —tests none —prefix=$PWD/osx —no-third-party
android
android armv8-a
export NDK=/Users/bytedance/Downloads/android-ndk-r21b
export TOOLCHAIN=$NDK/toolchains/llvm/prebuilt/darwin-x86_64
export TARGET=aarch64-linux-android
export API=21
export AR=$TOOLCHAIN/bin/$TARGET-ar
export AS=$TOOLCHAIN/bin/$TARGET-as
export CC=$TOOLCHAIN/bin/$TARGET$API-clang
export CXX=$TOOLCHAIN/bin/$TARGET$API-clang++
export LD=$TOOLCHAIN/bin/$TARGET-ld
export RANLIB=$TOOLCHAIN/bin/$TARGET-ranlib
export STRIP=$TOOLCHAIN/bin/$TARGET-strip
./coinbrew build Clp \
—host=$TARGET \
—enable-static \
—disable-shared \
—prefix=$PWD/android/armv8-a \
—tests none \
—no-third-party
android armv7-a
export NDK=/Users/bytedance/Downloads/android-ndk-r21b
export TOOLCHAIN=$NDK/toolchains/llvm/prebuilt/darwin-x86_64
export TARGET=armv7a-linux-androideabi
export API=21
export AR=$TOOLCHAIN/bin/arm-linux-androideabi-ar
export AS=$TOOLCHAIN/bin/arm-linux-androideabi-as
export CC=$TOOLCHAIN/bin/$TARGET$API-clang
export CXX=$TOOLCHAIN/bin/$TARGET$API-clang++
export LD=$TOOLCHAIN/bin/arm-linux-androideabi-ld
export RANLIB=$TOOLCHAIN/bin/arm-linux-androideabi-ranlib
export STRIP=$TOOLCHAIN/bin/$arm-linux-androideabi-strip
./coinbrew build Clp \
—host=$TARGET \
—enable-static \
—disable-shared \
—prefix=$PWD/android/armv7-a \
—tests none \
—no-third-party
local
static
./coinbrew build Clp —enable-static —disable-shared —tests none —prefix=$PWD/static —no-third-party
dynamic
./coinbrew build Clp —prefix=$PWD/dynamic —no-third-party —verbosity 4