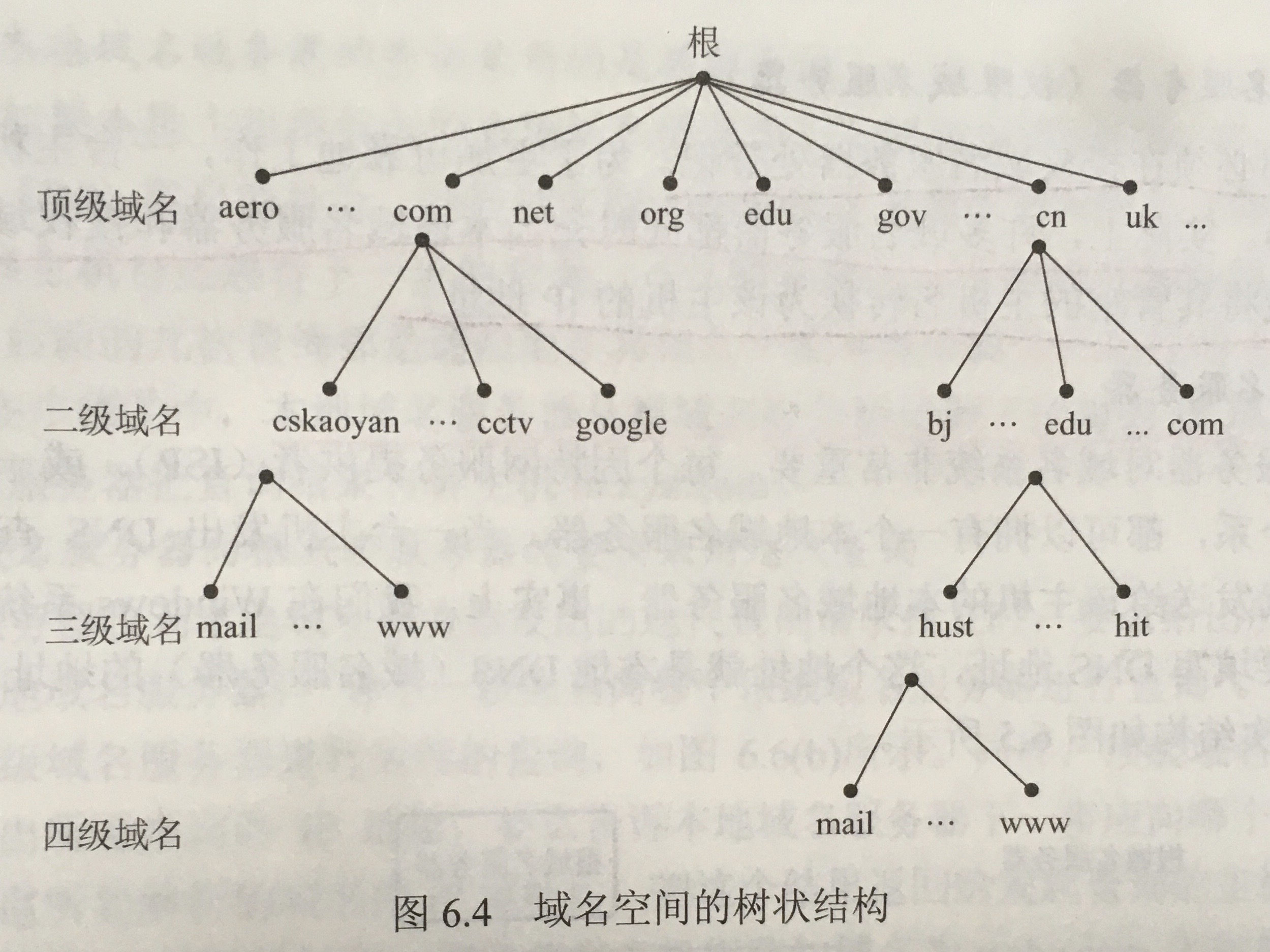
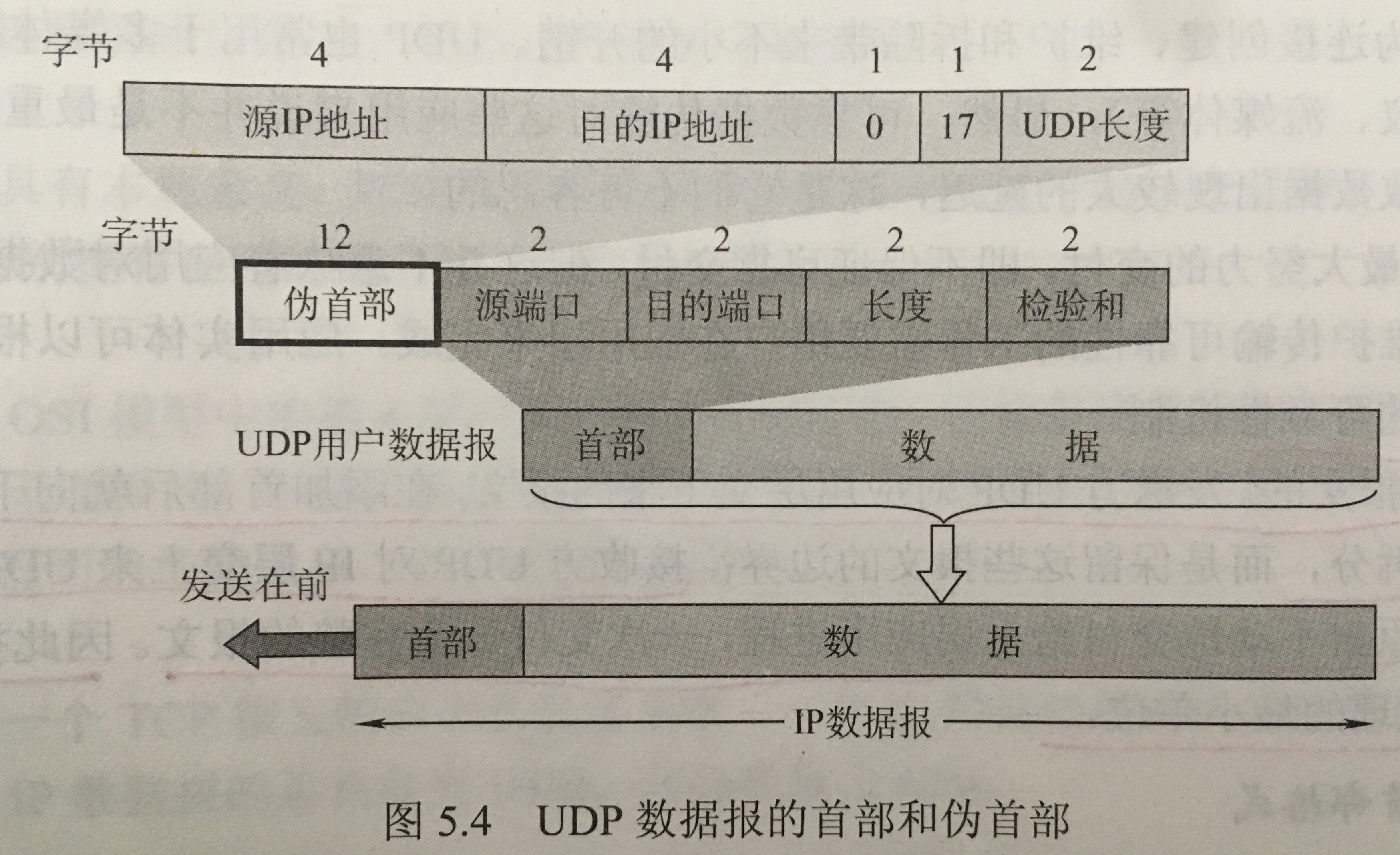
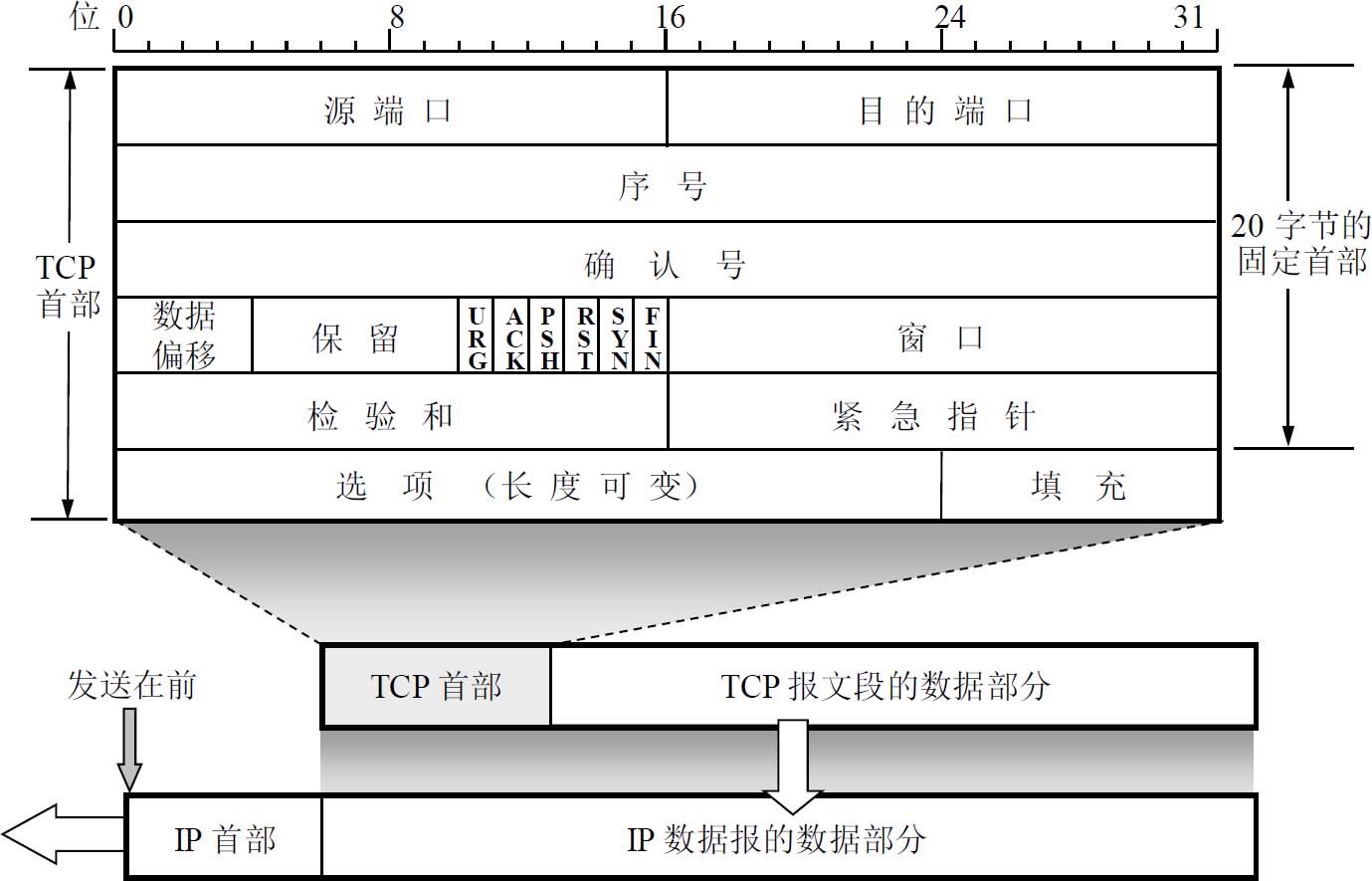
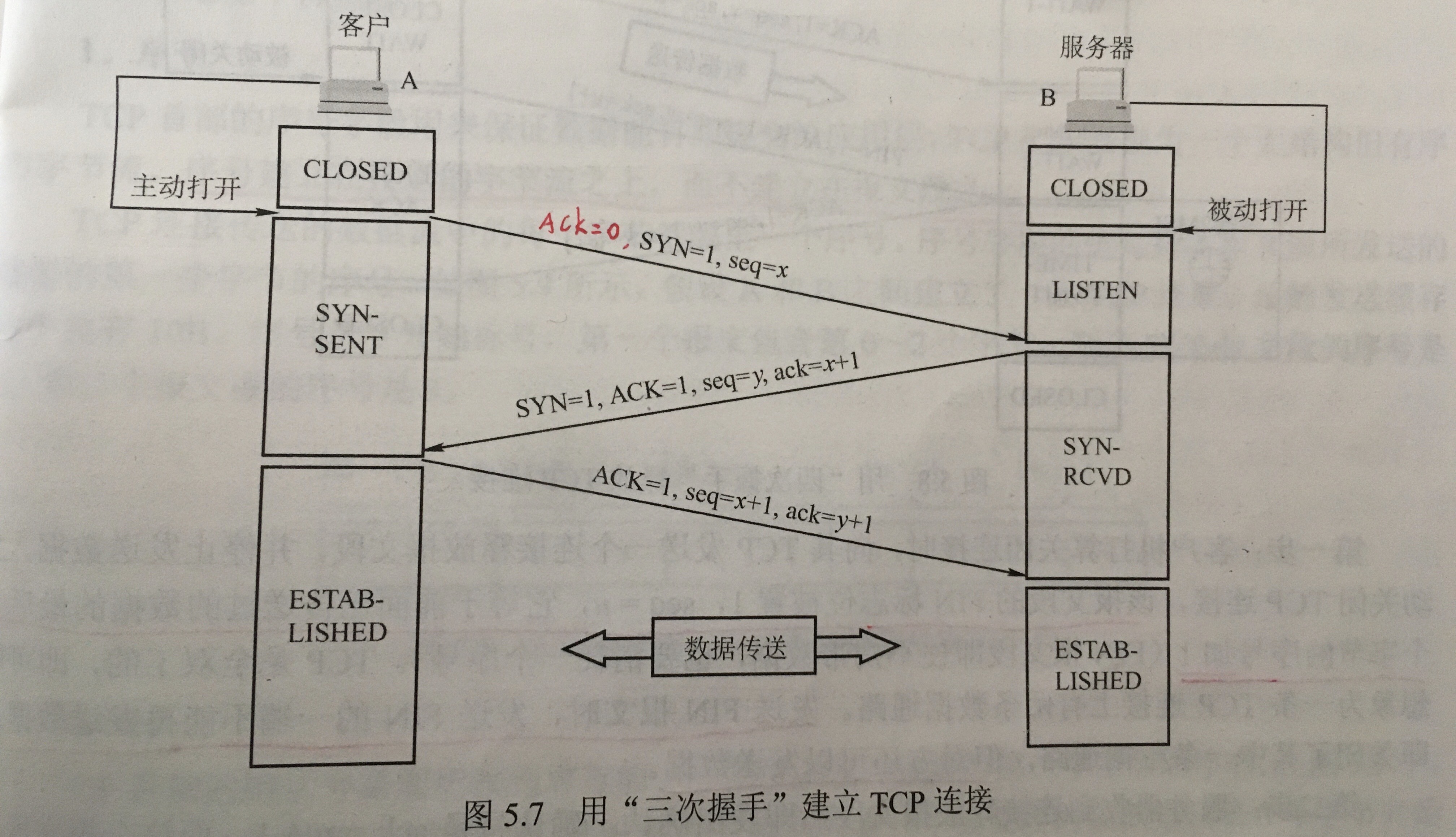
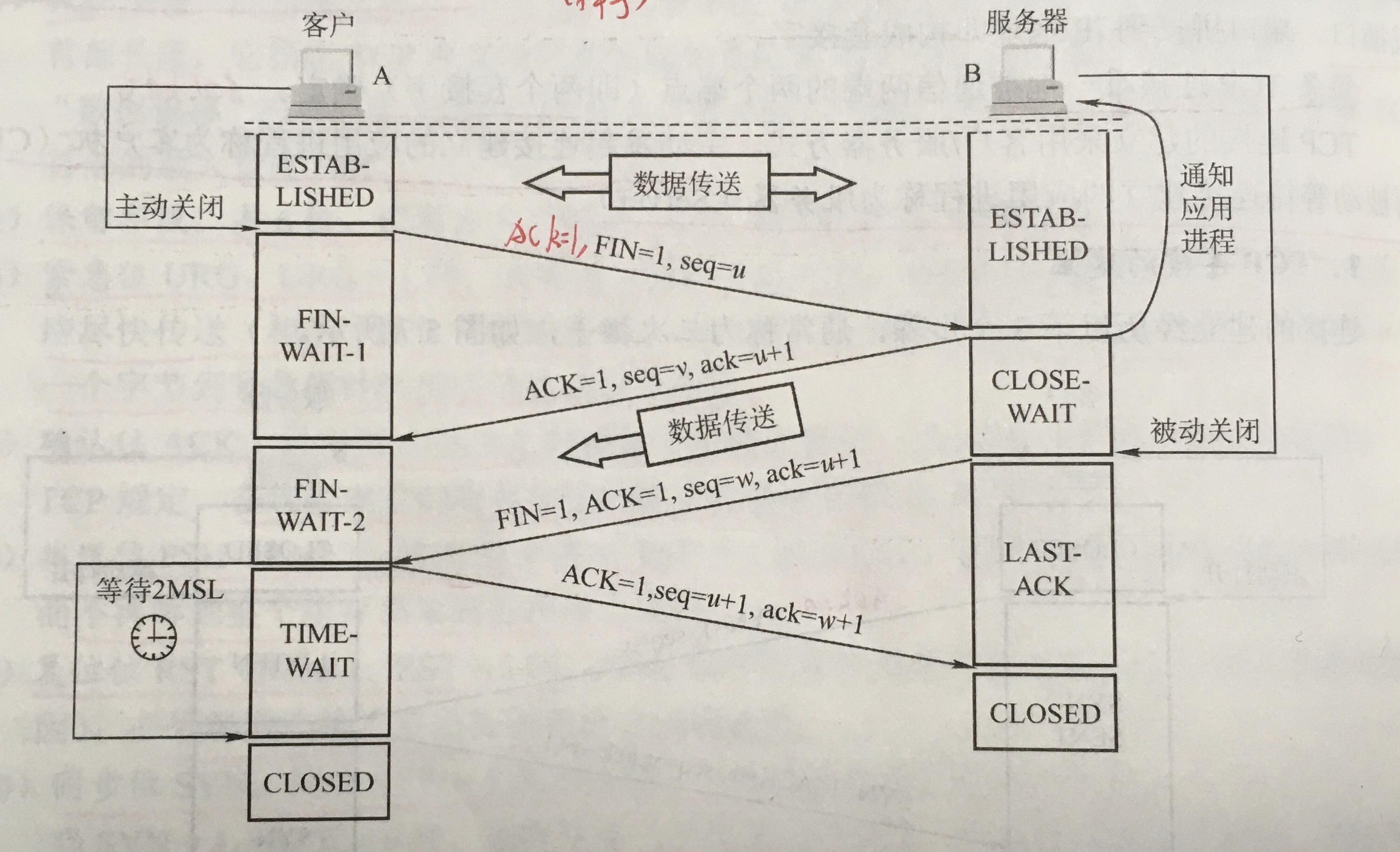
Creating Meshes
The current way to create a mesh is using MeshBuilder
1 | const mesh = BABYLON.MeshBuilder.Create < MeshType > (name, options, scene) |
The options object will have different properties according to the type of mesh and can be empty . The scene parameter is optional and defaults to the current scene.
Create Set Shapes
Box
1 | const box = BABYLON.MeshBuilder.CreateBox("box", options, scene) |
Tiled Plane
1 | const tiledPlane = BABYLON.MeshBuilder.CreateTiledPlane("plane", options, scene) |
Tiled Plane is good example for understanding the options parameter, see more in this doc
Ground From Height Map
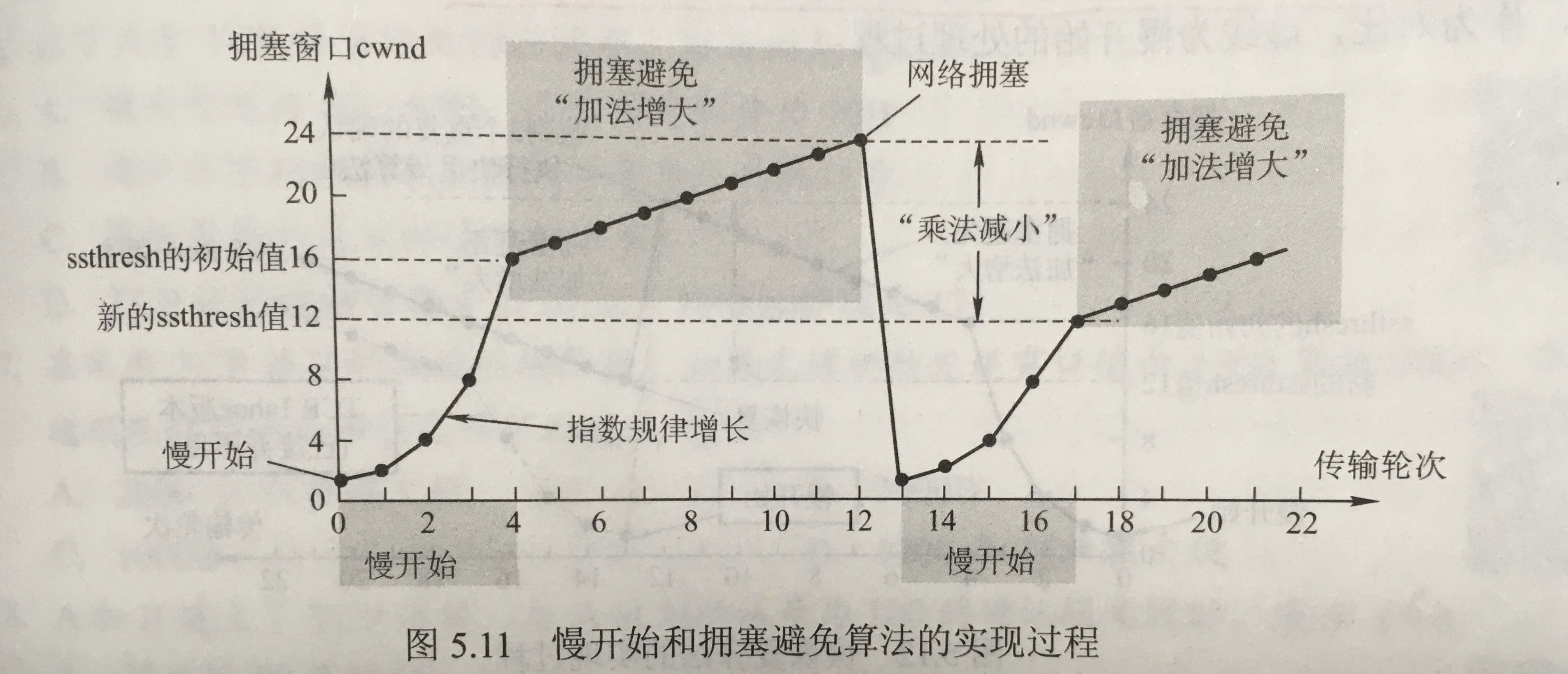
When the ground is created using groundFromHeightMap the surface of the ground can be perturbed by a grayscale image file called a height map. Lighter areas are displayed higher than darker areas. This is a way of creating hills and valleys on your ground.
1 | const ground = BABYLON.MeshBuilder.CreateGroundFromHeightMap("gdhm", url_to_height_map, options, scene) |
see more in this docs
Create Parametric Meshes
These meshes are so called because their shape is defined by a an array of vector3 parameters and can be irregular in nature. You can produce a series of broken or unbroken lines across 3D space. In 2D you can produce an horizontal irregular convex or concave polygon, which may be extruded vertically into 3D. It is also possible to extrude the 2D outline along a path that travels in 3D space and vary its rotation and scale as it travels the path. You can also ‘lathe’ an outline to give a shape with rotational symmetry.
1 | const mesh = BABYLON.MeshBuilder.Create<MeshType>(name, options, scene) |
Extrusion
Lathe
Polygon
Creating Polyhedra Shapes
Create Custom Meshes
Vertex Normals
Mesh Transformation
Centered On
Mesh Rotation
When you use the rotation method on a mesh then the rotation is applied in local space, the order is - a rotation of beta about the local y axis, then alpha about the local x axis and finally a rotation of gamma about the local z axis.
Coordinate Transformation
The first step in understanding coordinate transformation Babylon.js is to understand how the data describing a mesh is stored. The positions of each vertex is kept in an array of coordinates in the local space of the mesh. Each transformation applied to the mesh is stored in a matrix called the World Matrix. For each rendered frame the current World Matrix is used on the local space vertex data to obtain the world data for the mesh. Except for exceptional circumstance such as baking a transformation or a user updating it, the mesh vertex data remains unchanged.
Baking Transformations
Usually, within Babylon.js, positioning, rotating and scaling a mesh changes its world matrix only and the vertex position data of a mesh is left unchanged.
In certain situations you might be interested in applying a transform (position, rotation, scale) directly to the mesh vertices and leave world matrix unchanged. This is called baking.
Unless you have good reasons to use baking transformations then your are better with parents and pivots.
Parents and Pivots
When parent property is set on a mesh, transforming the parent will apply the same transformations to the child. Translations, rotations and scaling of the child will take place relative to the local origin of the child. Setting the position of the child will be relative to the local origin of the parent. In simpler terms, moving the child will not move the parent and moving the parent will move the child.
TransformNode
A TransformNode is an object that is not rendered but can be used as a center of transformation. This can decrease memory usage and increase rendering speed compared to using an empty mesh as a parent and is less complicated than using a pivot matrix.
Parent and Children
To add or remove a parent, it’s better to directly set the parent of target mesh, instead calling setParent() and addChild(), as those two method may cause unwanted transformation.
1 | meshC.parent = meshP; // 1 |
Copies, Clones and Instances
Clones
This simply creates a deep copy of the original mesh and saves memory by sharing the geometry(vertices). Each clone can have its own material and transformation.
Cloning With the Solid Particle System
There is more to the Solid Particle System (SPS) than just producing multiple copies of a mesh and these are considered in full in the Particles section. The SPS places multiple copies of a mesh all together into just one mesh. This means that instead of multiple draw calls there is just one draw call for the single mesh.
1 | SPS = new BABYLON.SolidParticleSystem("SPS", scene); //create the SPS |
instances
Instances are an excellent way to use hardware accelerated rendering to draw a huge number of identical meshes (let’s imagine a forest or an army). Each instance has the same material as the root mesh. They can vary on the following properties:
positionrotationrotationQuaternionsetPivotMatrixscaling
1 | let newMesh = someMesh.createInstance("name") |
instancing a glTF object
When you instanciate a glTF object, you need to make sure that the new instance will be under the same parent or you need to remove the parent from the source object.
This is because every gltf file comes from a right handed world. To get it into Babylon.js left handed world, we are adding an arbitrary parent that is adding a negative scale on z.
So when instancing a glTF object you have to (either):
- Call
source.setParent(null) - Or call
newInstance.setParent(source.parent)
Thin Instances
instances are an excellent way to use hardware accelerated rendering to draw a huge number of identical meshes.
However, regular instances still have a performance penalty on the javascript side because each instance is its own object (InstancedMesh): if you have 10000 instances in your scene, the engine must loop over all those objects to make a number of processing
Thin instances don’t create new objects so you don’t incur any penalty on the javascript side by having thousands of them. This performance increase does come with a cost:
- all thin instances are always all drawn (if the mesh is deemed visible) or none. It’s all or nothing.
- adding / removing a thin instance is more costly than with
InstancedMesh
Thin instances should be used when you need a lot of static instances that you know won’t change often / at all. Think of the seats of a stadium
A thin instance is represented by a position/rotation/scaling data packed into a matrix.
1 | let matrix = BABYLON.Matrix.Translation(-2, 2, 0); |
Note that someMesh itself is not rendered. If you want to render it, use thinInstanceAddSelf():
1 | someMesh.thinInstanceAddSelf(); |
Levels Of Detail
This feature allows you to specify different meshes based on distance to viewer (by default), or screen coverage.
1 | someMesh.addLODLevel(15, anotherLessLODMesh); |
The first parameter used with addLODLevel defines the distance to the camera. Each level is independent and can have its own material. By defining a level of detail to null, you disable rendering of the current mesh when it is viewed beyond the indicated distance to camera.
When a mesh is used as a level of detail for another mesh, it is linked to it and cannot be rendered directly.
You can remove a LOD level by using removeLODLevel:
1 | baseMesh.removeLODLevel(anotherLessLODMesh); |
You can alternatively add LOD levels by specifying screen coverage cutoff limits. Screen coverage is computed as a ratio between 0 and 1 of the mesh’s rendered screen surface area, over the total screen surface area. This method has the notable advantage over distance comparison to be scale-independant, as a big object rendered from a long distance, can still be big on the screen.
To specify that your LOD levels use screen coverage instead of distance, use:
1 | baseMesh.useLODScreenCoverage = true; |
Interactions
To avoid costly calculation by checking many details on a mesh, Babylon engine creates a bounding box around the object, and tests for intersection between this box, and the colliding mesh.
Mesh intersections
We will use the intersectsMesh() function, with two parameters: the mesh to be checked, and the precision of the intersection (boolean), which determines what kind of bounding box will be used.
1 | mesh1.intersectsMesh(mesh2, false) |
The other function you can use is intersectsPoint() with a specific point
1 | mesh.intersectsPoint(pointToIntersect) |
Mesh Picking
Raycasts
1 | let ray = new BABYLON.Ray(origin, direction, length); |
secon parameter predicate is a filter to choose which meshes will be selectable
1 | function predicate(mesh) { |
in the code example above, the mesh1 and mesh2 will not be hit by the ray.
We can use scene.multiPickWithRay if we don’t want that the ray to stop at the first obstacle:
1 | let hitInfoList = scene.multiPickWithRay(ray); |
Node Geometry
The NodeGeometry feature was inspired by Blender Geometry Nodes where you can use a node system to build geometry procedurally.
Several reasons to use Node Geometry:
- The cost of downloading assets on the web is a strong limiting factor. Procedural data can help solve that by limiting the download to the core pieces that are assembled later by the
NodeGeometrysystem - The system is dynamic and can produce infinite variants at run time. While there are many digital content creation tools that can create procedural meshes with the same infinite possibilities, the limiting factor again becomes downloading assets created offline. Examples would be terrain or vegetation generation.
- It allows a new way of modelling in Babylon.js by assembling core shapes and playing around with a node system
How to use
The NodeGeometry class is an utility class, meaning it is autonomous and does not require access to an engine or a scene.
1 | const nodeGeometry = new BABYLON.NodeGeometry("my node geometry"); |
Once created, the system will expect you to create a flow from a source to an endpoint.
By default, the NodeGeometry system supports the following sources:
- Box
- Capsule
- Cylinder
- Disc
- Grid
- Icosphere
- Mesh
- Plane
- Sphere
- Torus
1 | // Create node geometry |
It better to use a Node Geometry Editor to create visual graph and generate code. See more about this editor
Drawing Bounding Boxes
To draw the bounding box around your mesh, all you need to do is set the showBoundingBox property to true.
1 | mesh.showBoundingBox = true; |
BillBoard Mode
Billboard is a special mode for meshes, ensuring that the mesh is always facing towards the camera. This is commonly used to display information to the user, sprites or particles for instance.
1 | mesh.billboardMode = BABYLON.Mesh.BILLBOARDMODE_ALL |
Billboard Mode Value
| value | Type |
|---|---|
| 0 | BILLBOARDMODE_NONE |
| 1 | BILLBOARDMODE_X |
| 2 | BILLBOARDMODE_Y |
| 4 | BILLBOARDMODE_Z |
| 7 | BILLBOARDMODE_ALL |
Decals
Decals are usually used to add details on meshes (bullets hole, local details, etc…). A decal is either a mesh produced from a subset of a previous one with a small offset in order to appear on top of it, or an additional texture applied to a mesh (a “decal map”).
Mesh Decals
1 | const decal = BABYLON.MeshBuilder.CreateDecal("decal", mesh, options, scene); |
Decal Maps
Decal Maps are new in Babylon.js since 5.49.0. They are a way to add decal to a mesh without having to create a new mesh. It is a texture that is applied to a mesh in such a way that it appears to be a decal on the mesh.
1 | const decalMap = new BABYLON.MeshUVSpaceRenderer(mesh, scene); |
Highlightindg Meshes
Before anything else, you must ensure that your engine was created with stencil on:
1 | const engine = new BABYLON.Engine(canvas, true, { stencil: true }); |
In the most basic shape, you only need to instantiate one highlight layer in your scene and add the meshes you want to highlight in it.
1 | const hl = new BABYLON.HighlightLayer("hl1", scene); |
Making Meshes Glow
Emissive meshes are equivalent to self lit meshes. Both the emissive color and texture of the material determine how the mesh will self lit.
Only one line is needed to make all the emissive parts of a scene glow:
1 | const gl = new BABYLON.GlowLayer("glow", scene); |
To control the intensity of the color in the glow layer, you can use the dedicated property
1 | gl.intensity = 0.5; |
In order to control the shape of the blur, you can rely on the creation option:
- mainTextureRatio: Multiplication factor applied to the canvas size to compute the render target size used to generate the glowing objects (the smaller the faster).
- mainTextureFixedSize: Enforces a fixed size texture to ensure resize independant blur to prevent the shape of the blur to change according to the target device size.
- blurKernelSize: How big is the kernel of the blur texture.
1 | const gl = new BABYLON.GlowLayer("glow", scene, { |
Controlling glow color per mesh
By default the glow layer will use emissive texture and emissive color to generate the glow color of every active mesh. But you can override this behavior with the following callbacks:
customEmissiveColorSelector: (mesh: Mesh, subMesh: SubMesh, material: Material, result: Color4) => void: Callback used to let the user override the color selection on a per mesh basiscustomEmissiveTextureSelector(mesh: Mesh, subMesh: SubMesh, material: Material) => Texture: Callback used to let the user override the texture selection on a per mesh basis
1 | gl.customEmissiveColorSelector = function (mesh, subMesh, material, result) { |
Anti Aliasing
Depending on your setup, some aliasing artifacts might appear in the glow. To prevent this behavior, you can specify the number of samples to use for MSAA on the main render target. Please note that it will only work on WebGL2 capable browsers.
1 | const gl = new BABYLON.GlowLayer("glow", scene, { |
Exclude or Include Mesh
Some helper functions have been introduced to exclude or only include some meshes from the scene.
1 | gl.addExcludedMesh(mesh); |
Using the function will automatically switch mode and only render the included meshes. Kind of like the conception in light.
Merging Meshes
To easily merge a number of meshes to a single mesh use the static MergeMeshes of the Mesh class:
1 | const newMesh = BABYLON.Mesh.MergeMeshes( |
Facet Data
A mesh can have some planar faces. For example, a box has 6 sides, so 6 planar squared faces. Each of its faces are drawn at the WebGL level with 2 triangles. We call “facets” these elementary triangles.
FacetData is a feature that can be enabled on a mesh. As it requires some extra memory, it’s not enabled by default. This feature provides some methods and properties to access each facet of a mesh, like the facet positions, normals.
To enable this feature, just call once updateFacetData().
1 | const mesh = BABYLON.MeshBuilder.CreateTorusKnot("t", { radius: 2.0 }, scene); |
If the mesh belongs to some parent-child relationship, the feature is then not enabled for its parents or children.
Unless the mesh is updated or morphed afterwards, you don’t need to call this method anymore once it has been done.
you can disabled it to release the memory with mesh.disableFacetData().
1 | mesh.updateFacetData(); |
Facet Data
You can get the position of the i-th facet of a mesh with getFacetPosition(i). This returns a new Vector3 that is the world coordinates of the facet center.
1 | const pos = mesh.getFacetPosition(50); |
If you don’t want to allocate a new Vector3 per call, you can use getFacetPositionToRef(i, ref) instead.
1 | const pos = BABYLON.Vector3.Zero(); |
All the methods dealing with the world coordinates use the mesh world matrix. As you may know, this matrix is automatically computed on the render call.
If you’ve just moved, scaled or rotated your mesh before calling the facetData methods using the world values and you’re not sure about this, you can ever force the world matrix computation.
1 | mesh.rotate.y += 0.2; // the mesh will be rotated on the next render call, but I need a rotated normal |
Morphing
When talking about morphing, we mean here changing the vertices positions of an existing mesh. Indices remain unchanged.
- To create an updatable mesh, it is mandatory to set its updatable parameter to true when calling CreateXXX() method.
- To update then an existing parametric shape, we just have to use the same CreateXXX method as we used to construct it.
- Only the existing mesh and the data relative to new positions (path, pathArray, array of points) must be passed to this method, the other parameters are ignored.
- If we want to morph the mesh, we then use the CreateXXX() method within the render loop.
In this case, it is important not to allocate new memory each frame : we access our arrays by indexes and just change values instead of creating new arrays, we access existing objects instead of instantiating new ones, etc. We also take care about the weight of each object (number of sides, number of vertices, etc).
More speed
The former CreateXXX() update functions try to be as much optimized as possible to run fast in the render loop. However, you may need some more speed for any reason (huge mesh with dozens of thousands of vertices for instance). So, if your mesh doesn’t need to reflect the light (emissive color only for instance), you can skip the normals re-computation which is a CPU consuming process. Use then the freezeNormals() method just after your mesh is created :
1 | const tube = BABYLON.Mesh.CreateTube("tube", path, 3, 12, null, BABYLON.Mesh.NO_CAP, scene, true); |