第19条:不要把函数返回的多个值拆分到三个以上的变量中
python的unpacking机制允许python函数返回一个以上的值,函数返回一个以上的值的时候,实际上返回的是一个元组。
1 | def get_min_max(numbers): |
在返回多个值的时候,可以用带星号的表达式接收那些没有被普通变量捕获到的值(参考第13条)
1 | def get_avg_ratio(numbers): |
当我们用超过三个变量去接收函数的返回值时,会很容易出现将顺序弄错的情况。所以一般来时,一个元组最多只拆分到三个普通变量或者拆分到两个普通变量与一个万能变量(带星号的变量)。假如要拆分的值确实很多,那最好还是定义一个轻便的类或namedtuple(参见第37条),并让函数返回这样的实例。
第20条:遇到意外状况时应该抛出异常,不要返回None
编写工具函数(utility function)时,许多python程序员都爱用None这个返回值来表示特殊情况。对于某些函数来说,这或许有几分道理。例如,我们要编写一个辅助函数计算两数相除的结果,在除数是0的情况下,返回None似乎合理,因为这种除法的结果是没有意义的。
1 | def careful_devide(a, b): |
但是,如果传给careful_divide函数的被除数为0时,会怎么样呢?在这种情况下,只要除数不为0,函数返回的结果就应该是0。但是问题时,别人在使用这个工具函数时,在if表达式中不会明确判断返回值是否是None,而是去判断返回值是否相当于False:
1 | x, y = 0, 5 |
上面这种if语句,会把函数返回0的情况和返回None的情况一样处理。由于这种写法经常出现在python代码里,因此,像careful_divide这样,用None来表示特殊情况的函数是很容易出错的。有两种办法可以减少这样的错误。
第一种,利用二元组把计算结果分成两部分返回,元组的首个元素表示操作是否成功,第二个元素表示计算的实际值:
1 | def careful_divide(a, b): |
但是,有些调用方总喜欢忽略元组的第一个部分。第二种方法比刚才那种更好,就是不采用None表示特例,而是向调用方抛出异常,让他们自己去处理。
1 | def careful_divide(a, b): |
我们还可以利用类型注解指明函数返回float类型,这样就对外说明不会返回None了,但是,我们无法在函数的接口上说明函数可能抛出哪些异常,所以,我们只好把有可能抛出的异常写在文档里面,并希望调用方能够根据这份文档适当得捕获相关的异常(参见第84条)。
1 | def careful_divide(a: float, b:float) -> float: |
总结:用返回值None表示特殊情况是很容易出错的,因为这样的值在条件表达式里面没法与0、空字符串、空数组之类的值进行区分,这些值都相当于False。
个人觉得作者在此处使用的代码示例不是很好,这个抛出异常版本的careful_divide函数根据没啥实际用处,使用者还不如直接去捕获ZeroDivisionError,作者的目的可能只是为了简明得解释这条建议。
第21条:了解如何在闭包里面使用外围作用域中的变量
假设,现在有一个需求,我们要给列表中的元素排序,而且要优先把在另外一个群组的元素放在其他元素的前面。实现这种做法的一种常见方案,是把辅助函数通过key参数传给列表的sort方法,让这个方法根据辅助函数返回的值来决定元素在列表中的先后顺序,辅助函数先判断当前元素是否处在重要群组里,如果在,就把返回值的第一项写成0,让它能够排在不属于这个组的那些元素之前
1 | def sort_priority(values, group): |
在sort_priority函数中,引用了外部函数的group参数,在一个内部函数中,对外部作用域的变量进行引用,那么内部函数就被认为是闭包。
假设现在需求新增,sort_priority函数还需要告诉我们,列表里面是否有位于重要群组之中,那么第一个想法就是添加一个标志位:
1 | def sort_priority(values, group): |
虽然排序结果没有问题,但是却发现标志本应该为True,但是返回的确是False。
在表达式中引用某个变量时,Python解释器会按照下面的顺序,在各个作用域(scope)里面查找这个变量,以解析这次引用(变量出现在=右边时)。
当前函数作用域
外围作用域(例如包含当前函数的其他函数所对应的作用域)
包含当前代码的那个模块所对应的作用域(也叫全局作用域,global scope)
内置作用域(built-in scope,也就是包含len与str等函数的那个作用域)
如果这些作用域中都没有定义名称相符的变量,那么程序就抛出NameError异常。
当对变量进行赋值时(变量出现在=左边),需要分两种情况处理:如果变量已经定义在当前作用域中,那么直接把新值赋给它就行了。如果当前作用域中不存在这个变量,那么即使外围作用域里有同名的变量,Python也还是会把这次赋值操作当成变量的定义来处理。这会产生一个重要的效果,也就是说,Python会把包含赋值操作的这个函数当作新定义的这个变量的作用域。这也就解释了为什么found还是为False。
这种问题有时也称为作用域bug(scoping bug),Python新手可能认为这样的赋值规则很奇怪,但实际上Python是故意这么设计的,因为这样可以防止函数的局部变量污染外围模块,假设不这么做,那么函数里的每条赋值语句都有可能影响全局作用域的变量,这不仅混乱,而且会让全局变量之间彼此交互影响,从而导致更多难以探查的bug。
Python有一种特殊的写法,可以把闭包里面的数据赋给闭包外面的变量。用`nonlocal`描述变量,就可以让系统在处理针对这个变量的赋值操作时,去外围作用域查找。然而,nonlocal有个限制,就是不能侵入模块级别的作用域(以防污染全局作用域)。1 | def sort_priority(values, group): |
nonlocal语句清楚地说明,我们要把数据赋给闭包之外的变量。有一种跟它互补的语句,叫做global,用这种语句描述某个变量后,在给这个变量赋值时,系统会直接把它放到模块作用域中。
1 | def to_global(): |
1 | def log(msg, values): |
1 | def log(msg, *values): |
1 | numbers = [1, 2, 3] |
1 | def my_generator(): |
1 | def log(sequence, msg, *values): |
1 | def remainder(number, divisor): |
1 | remiander(20, 7) |
1 | remainder(number=20, 7) |
1 | remainder(20, number=7) |
如果有一份字典,而且字典里面的内容能够用来调用remainder这样的函数,那么可以吧**运算符加在字典前面,这会让Python把字典里面的键值以关键字参数的形式传给函数。
1 | my_kwargs = { |
调用函数时,带**操作符的参数可以和位置参数或关键字参数混用,只要不重复指定就行。
1 | my_kwargs = { |
也可以对多个字典分别施加**操作,只要这些字典所提供的参数不重叠就好。
1 | my_kwargs = { |
1 | def print_parameters(**kwargs): |
1 | def calculate_flow_rate(weight_diff, time_diff, period=3600, units_per_kg=2.2): |
1 | from time import sleep |
要想在Python里实现这种效果,惯用的办法是把参数的默认值设为None,同时在docstring文档里面写清楚,这个参数为None时,函数会怎么运作(参见第84条)。给函数写实现代码时,在内部对参数进行判断。
1 | def log(msg, when=None): |
把参数的默认值写成None还有个重要的意义,就是用来表示那种以后可能由调用者修改内容的默认值(例如某个可变容器)。例如,我们要写一个函数对采用JSON格式编码的数据进行解码。如果无法解码,那么就返回调用时所指定的默认结果:
1 | import json |
这样的写法与前面的datetime.now()的例子有同样的问题,系统只会计算一次default参数(在加载这个模块时),所有每次调用这个函数时,给调用者返回的都是一开始分配的那个字段,这就相当于凡是以默认值返回来调用这个函数的代码都共用的同一份字典。这会让程序出现奇怪的效果:
1 | foo = decode('bad data') |
我们的本意是让这两次操作得到两个不同的空白字典,但是实际上foo和bar是同一个字典。要解决这个问题,可以把默认值设置为None,而且在docstring文档里面说明,函数在这个值为None时会怎么做:
1 | def decode(data, default=None): |
第25条:用只能以关键字指定和只能按位置传入的参数来设计清晰的参数列表
按关键字传递参数是Python函数的一项强大特性,这种关键字参数特别灵活,在很多情况下,都能让我们写出一看就冬的函数代码。
例如,计算两数相除的结果时,可能需要仔细考虑各种特殊情况。例如在除数为0的情况下,时抛出异常还是返回无穷;在结果益处的情况下,是抛出异常还是返回0:
1 | def safe_division(number, divisor, |
调用者可以根据自己的需要对ignore_overflow和ignore_zero_division参数进行指定,而且调用者使用关键字形式进行传递会让代码显得更清晰。但是,按照上面的函数定义形式,我们没有办法要求调用者必须按照关键字形式来指定这两个参数。他们还是可以用传统的写法,按位置给safe_divison函数传递参数。
1 | save_division(number, divisor, False, True) |
对于这种参数比较复杂的函数,我们可以声明只能通过关键字指定的参数(keyword-only argument),这样的话,写出来的代码就能清楚地反映调用者的想法了。这种参数只能用关键字来指定,不能按位置传递。具体操作方式是使用*符号把参数列表分成两组,左边是位置参数,右边是只能通过关键字指定的参数。
1 | def save_division(number, divisor, *, |
这时,如果按位置给只能用关键字指定的参数传值,那么程序就会出错。
1 | save_division(1.0, 0, True, False) |
但是,这样改依然还是有问题,因为在这个函数中,调用者在提供number和divisor参数时,既可以按位置提供,也可以按关键字提供,还可以把这两种方式混起来用:
1 | save_division(number=2, 5) |
在未来,也许因为扩展函数的需要,甚至是因为代码风格的变化,或许要修改这两个参数的名字。
1 | def save_division(numerator, denominator, *, |
这看起来只是字面上的微调,但之前所有通过关键字形式来指定这两个参数的调用代码,都会出错。其实最重要的问题在于,我们根本没有打算把number和divisor这两个名称纳入函数的接口;我们只是在编写函数时,随意挑了两个比较顺口的名称而已。
Python3.8引入了一项新特性,可以解决这个问题,这就是只能按位置传递的参数(positional-only argument)。这种参数与刚才的只能通过关键字指定的参数相反,它们必须按位置指定,绝不能通过关键字形式指定。具体操作方式是使用`/`符号表示左边的参数只能通过位置来指定:1 | def save_division(numerator, denominator, /, *, |
1 | def trace(func): |
1 |
|
1 | fibonacci(4) |
这样写确实能够满足要求,但是会带来一个我们不愿意看到的副作用。使用修饰器对fibonacci函数进行修饰后,fibonacci函数的名字本质上不再是fibonacci。
1 | print(fibonacci) |
这种现象解释起来并不困难。trace函数返回的,是它里面定义的wrapper函数,所以,当我们把这个返回值赋给fibonacci之后,fibonacci这个名称所表示的自然就是wrapper了。问题在于,这个可能会干扰需要利用反射机制来运作的工具。
例如,如果用内置的help函数来查看修饰后的fibonacci,那么打印出来的并不是我们想看的帮助文档,它本来应该打印前面定义时的那行’Return the n-th Fibonacci number文本才对’。
1 | help(fibonacci) |
对象序列化器也无法正常运作,因为它不能确定受修饰的那个原始函数的位置。
1 | import pickle |
想要解决这些问题,可以改用functool内置模块之中的wraps辅助函数来实现。wraps本身也是个修饰器,它可以帮助你编写自己的修饰器。把它运用到wrapper函数上面,它就会将重要的元数据全部从内部函数复制到外部函数。
1 | from functools import wraps |
现在我们就可以通过help函数看到正确的文档了,对象序列化器也可以正常使用,不会抛出异常了。

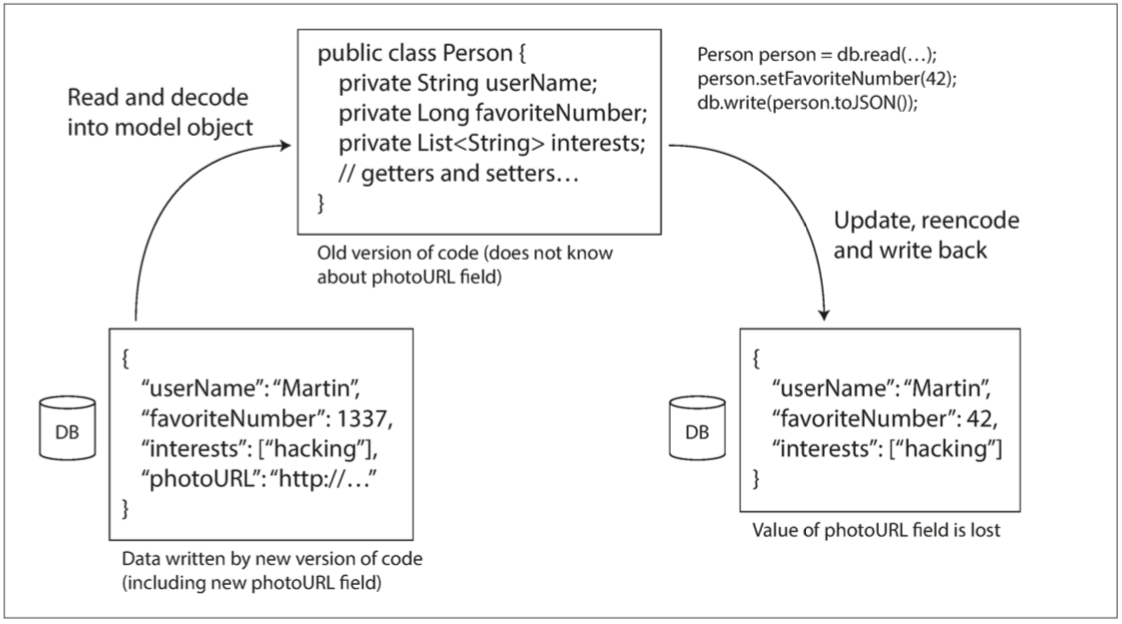
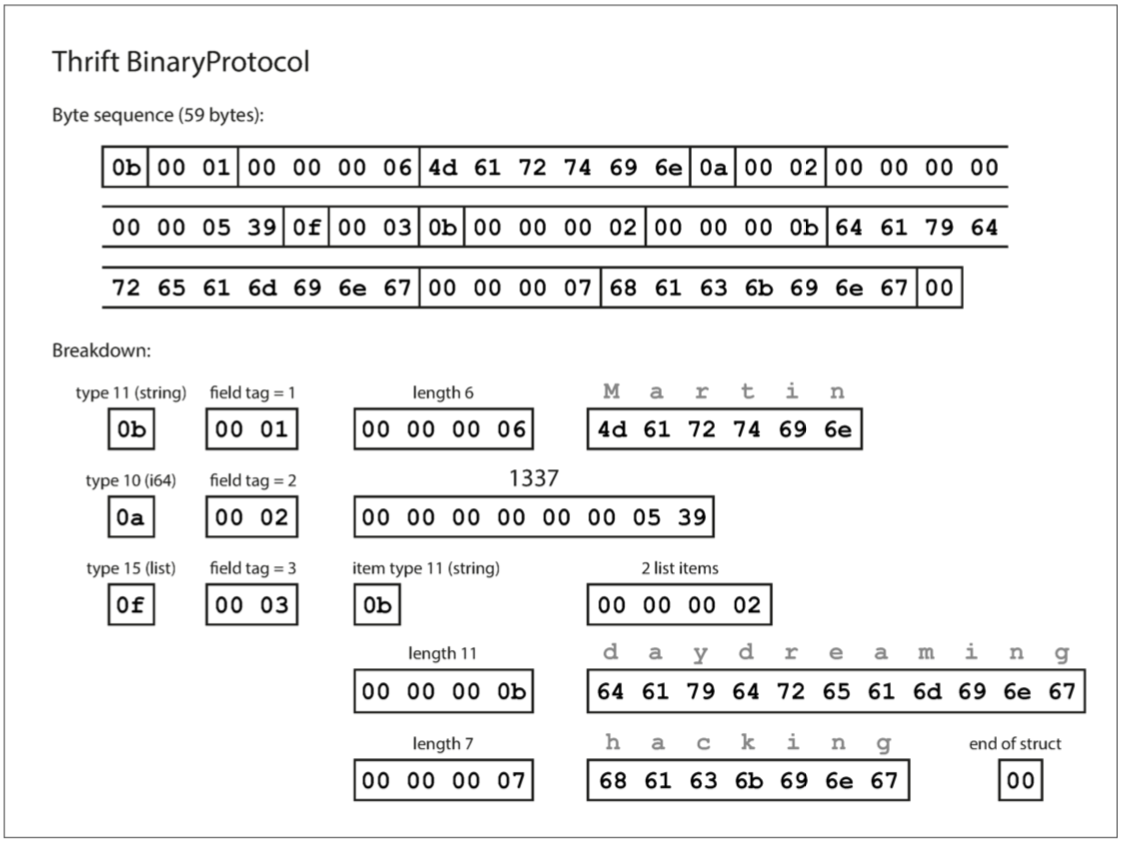 每一个字段都使用一个字节进行类型标注(用于指定它是字符串、整数、列表等),并且在需要时指定数据长度(包括字符串的长度、列表中的项数),数据中的字符串被编码成UTF-8格式的编码。与JSON相比,最大的区别是没有字段名,相反,编码数据包含数字类型的字段标签(1、2和3)。这些是模式定义中出现的数字,字段标签就像字段的别名,用来指示当前的字段。
上面的JSON文本编码需要占用81字节(去掉空格),而BinaryProtocol编码只需要59字节。
Thrift CompactProtocol编码在语意上等同于BinaryProtocol,它编码出来同格式的数据如下:
每一个字段都使用一个字节进行类型标注(用于指定它是字符串、整数、列表等),并且在需要时指定数据长度(包括字符串的长度、列表中的项数),数据中的字符串被编码成UTF-8格式的编码。与JSON相比,最大的区别是没有字段名,相反,编码数据包含数字类型的字段标签(1、2和3)。这些是模式定义中出现的数字,字段标签就像字段的别名,用来指示当前的字段。
上面的JSON文本编码需要占用81字节(去掉空格),而BinaryProtocol编码只需要59字节。
Thrift CompactProtocol编码在语意上等同于BinaryProtocol,它编码出来同格式的数据如下:
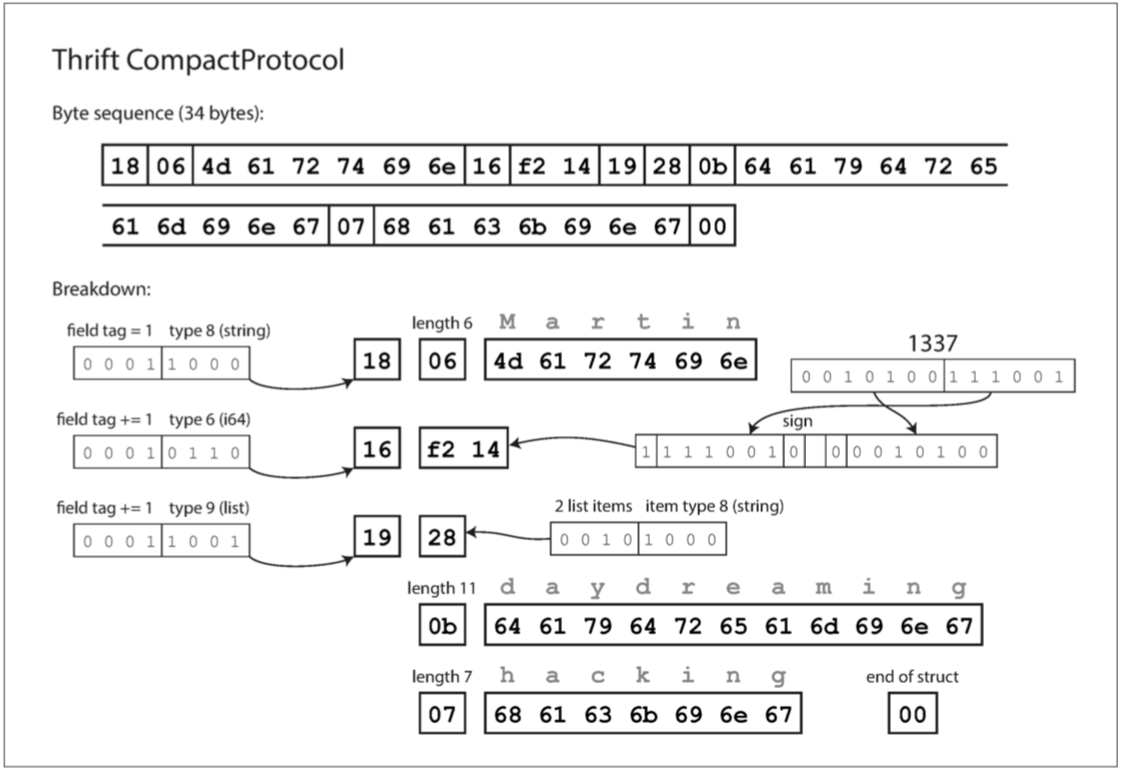 CompactProtocol编码出来的数据只有34字节,它通过将字段类型和字段标签打包到单个字节中,并使用可变长度整数来对数字进行编码。对数字1337,不使用全部8字节,而是使用两个字节进行编码,每字节的最高位来指示是否还有更多的字节(但是这也意味着每个字节都会失去一位有效数字,在某些情况下使用字节数还会比BinaryProtocol用得多)。
### Protocol Buffers的编码模式
Protocol Buffers只有一种二进制编码格式,对上面的JSON数据进行编码,它的结果如下:
CompactProtocol编码出来的数据只有34字节,它通过将字段类型和字段标签打包到单个字节中,并使用可变长度整数来对数字进行编码。对数字1337,不使用全部8字节,而是使用两个字节进行编码,每字节的最高位来指示是否还有更多的字节(但是这也意味着每个字节都会失去一位有效数字,在某些情况下使用字节数还会比BinaryProtocol用得多)。
### Protocol Buffers的编码模式
Protocol Buffers只有一种二进制编码格式,对上面的JSON数据进行编码,它的结果如下:
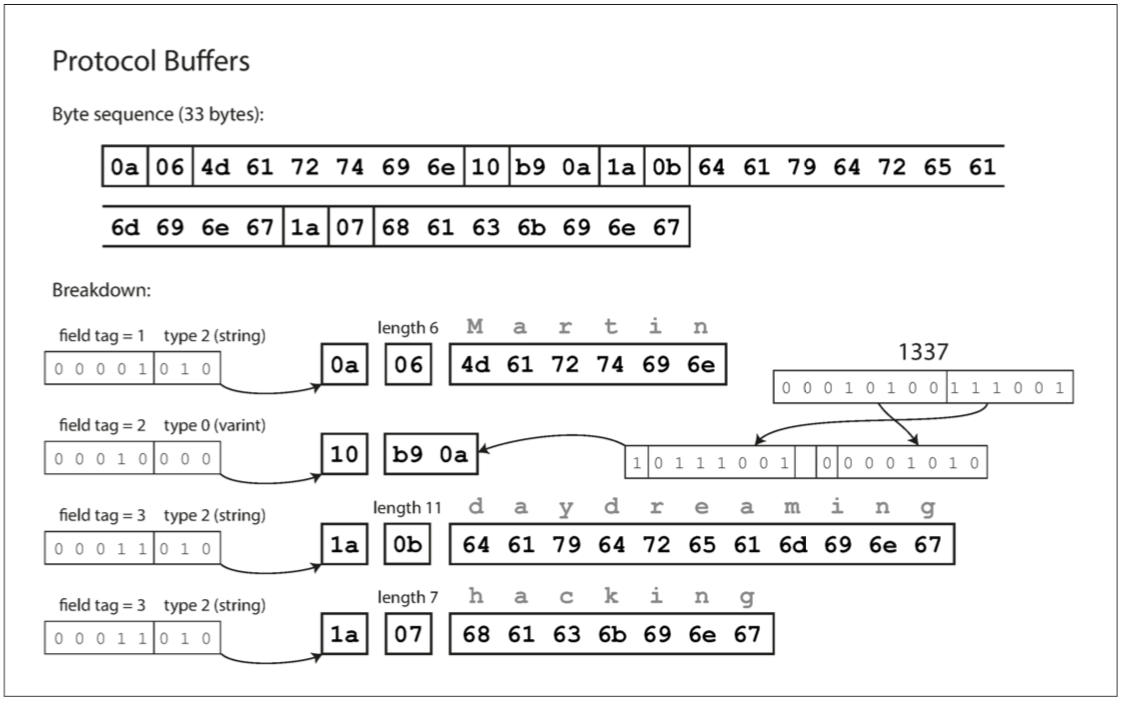 Protocol Buffers将字段类型和字段标签打包到单个字节中,并且数字类型只有变长编码的方式,并且对于list类型的编码是通过重复类型和字段tag来实现的,这一点和thirft也不同。
## 字段标签和字段增删
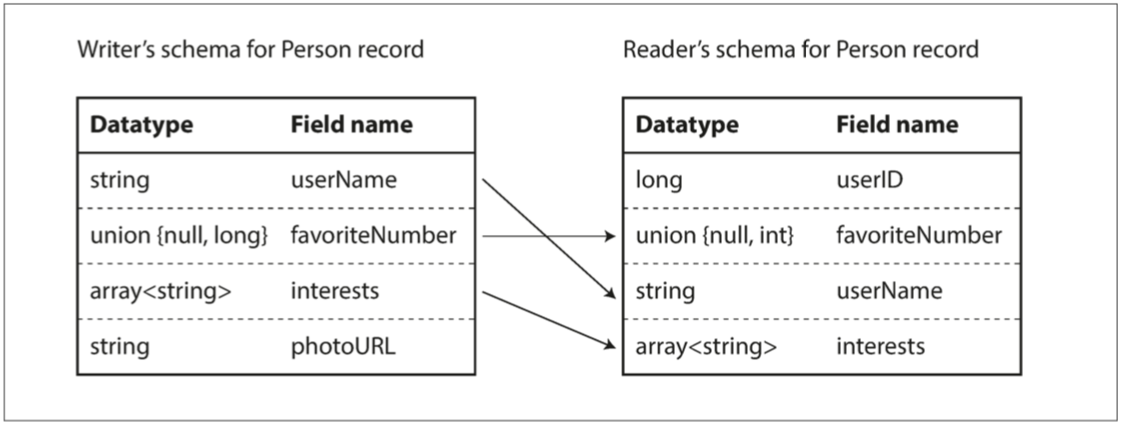
在Thrift和Protocol Buffers的编码中可以看到,字段标签对编码数据的含义至关重要,我们可以轻松更改模式中字段的名称,但不能随便更改字段的标签,因为编码永远不直接引用字段名称。
Protocol Buffers将字段类型和字段标签打包到单个字节中,并且数字类型只有变长编码的方式,并且对于list类型的编码是通过重复类型和字段tag来实现的,这一点和thirft也不同。
## 字段标签和字段增删
在Thrift和Protocol Buffers的编码中可以看到,字段标签对编码数据的含义至关重要,我们可以轻松更改模式中字段的名称,但不能随便更改字段的标签,因为编码永远不直接引用字段名称。






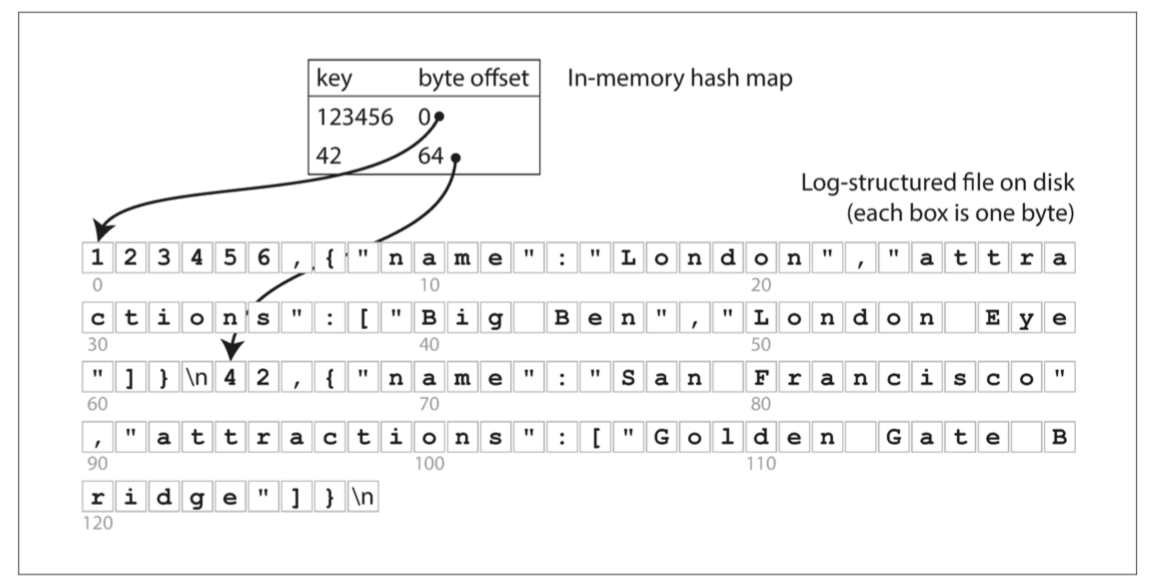 如果所有的key可以放进内存,只需要进行一次磁盘寻址,就可以将value从磁盘加载到内存。如果那部分的数据文件已经在文件系统的缓存中,则读取根本不需要任何的磁盘I/O。
但是,如果数据只追加到一个文件,那么如果避免最终用尽磁盘空间?一个好的解决方法是将日志分解成一定大小的段,当文件达到一定大小时就关闭它,并将后续写入到新的段文件中。同时,对于已经关闭的段文件,可以在每个段文件内部执行压缩操作,丢弃重复的键,只保留每个键在在段文件中最新的值,一个段文件压缩之后通常会使得段文件变得更小。在多个已经关闭的段文件直接可以执行合并操作,将多个压缩过的段文件合并成一个段文件。
如果所有的key可以放进内存,只需要进行一次磁盘寻址,就可以将value从磁盘加载到内存。如果那部分的数据文件已经在文件系统的缓存中,则读取根本不需要任何的磁盘I/O。
但是,如果数据只追加到一个文件,那么如果避免最终用尽磁盘空间?一个好的解决方法是将日志分解成一定大小的段,当文件达到一定大小时就关闭它,并将后续写入到新的段文件中。同时,对于已经关闭的段文件,可以在每个段文件内部执行压缩操作,丢弃重复的键,只保留每个键在在段文件中最新的值,一个段文件压缩之后通常会使得段文件变得更小。在多个已经关闭的段文件直接可以执行合并操作,将多个压缩过的段文件合并成一个段文件。

 这些冻结段的合并和压缩过程可以在后台线程中完成,而且运行时,仍可以使用未合并和压缩的段文件继续正常的读取。当合并过程完成后,再将读取请求切换到新的压缩合并完成的段文件上,旧的段文件则可以安全的删除。
每个段文件都有自己的内存hash map,用于将键映射到段文件中的偏移量。为了找到键的值,需要将所有段文件的hash表加载进内存,然后首先检查最新段的hash map,如果键不存在,检查第二新的段,以此类推。由于合并后可以维持较少的段数量,因此查询通常不需要检查很多的hash map。
还有很多的细节方面的考虑才能使得这个简单的想法在实际中行之有效。简而言之,在真正地实现中有以下重要问题:
* 如果要删除键和它关联地值,则必须在数据文件中追加一个特殊的删除记录。当合并日志段时,一旦发现删除记录,则会丢弃这个已删除键的所有值。
* 由于写入以严格的先后顺序追加到文件中,通常的实现方式是只有一个写线程。由于数据文件段是追加的,而且已经写入的数据是不可变的,所以它们可以被多个线程同时读取。
一个追加式的存储看起来似乎很浪费空间:为什么不原地更新文件,用新值覆盖旧值?但是,事实上,追加式的设计是一个不错的设计,原因有以下几点:
* 追加主要是顺序写,它通常比随机写快很多,特别是在旋转式磁性硬盘上。在某种程度上,属性写入在基于闪存的固态硬盘上也是合适的。
* 如果段文件是追加或不可变的,则并发和崩溃恢复要简单得多。里如果不必担心在重写值时发生崩溃的情况,留下一个包含部分旧值和部分新值混杂在一起的文件。
* 合并旧段可以避免随着时间推移数据文件出现碎片化的问题。
但是,哈希表索引也有其局限性:
* hash map必须全部放入内存,如果有大量的键,那么很可能超内存。原则上,可以在磁盘上维护hash map,但是,很难使磁盘上的hash map表现良好。它需要大量的随机访问I/O,并且哈希冲突时需要复杂的处理逻辑
## SSTable
对于单纯的将key-value按顺序添加到文件尾部的方式,如果在写入时对key进行排序,索引结构还是hash map。这样的存储形式就被成为SSTable(排序字符串表)。SSTable相对于单纯顺序添加的形式有以下几个优点:
1、在合并冻结段时更高效,由于每个段中的key都是有序的,合并时方法类似与归并排序merge sort的方式
这些冻结段的合并和压缩过程可以在后台线程中完成,而且运行时,仍可以使用未合并和压缩的段文件继续正常的读取。当合并过程完成后,再将读取请求切换到新的压缩合并完成的段文件上,旧的段文件则可以安全的删除。
每个段文件都有自己的内存hash map,用于将键映射到段文件中的偏移量。为了找到键的值,需要将所有段文件的hash表加载进内存,然后首先检查最新段的hash map,如果键不存在,检查第二新的段,以此类推。由于合并后可以维持较少的段数量,因此查询通常不需要检查很多的hash map。
还有很多的细节方面的考虑才能使得这个简单的想法在实际中行之有效。简而言之,在真正地实现中有以下重要问题:
* 如果要删除键和它关联地值,则必须在数据文件中追加一个特殊的删除记录。当合并日志段时,一旦发现删除记录,则会丢弃这个已删除键的所有值。
* 由于写入以严格的先后顺序追加到文件中,通常的实现方式是只有一个写线程。由于数据文件段是追加的,而且已经写入的数据是不可变的,所以它们可以被多个线程同时读取。
一个追加式的存储看起来似乎很浪费空间:为什么不原地更新文件,用新值覆盖旧值?但是,事实上,追加式的设计是一个不错的设计,原因有以下几点:
* 追加主要是顺序写,它通常比随机写快很多,特别是在旋转式磁性硬盘上。在某种程度上,属性写入在基于闪存的固态硬盘上也是合适的。
* 如果段文件是追加或不可变的,则并发和崩溃恢复要简单得多。里如果不必担心在重写值时发生崩溃的情况,留下一个包含部分旧值和部分新值混杂在一起的文件。
* 合并旧段可以避免随着时间推移数据文件出现碎片化的问题。
但是,哈希表索引也有其局限性:
* hash map必须全部放入内存,如果有大量的键,那么很可能超内存。原则上,可以在磁盘上维护hash map,但是,很难使磁盘上的hash map表现良好。它需要大量的随机访问I/O,并且哈希冲突时需要复杂的处理逻辑
## SSTable
对于单纯的将key-value按顺序添加到文件尾部的方式,如果在写入时对key进行排序,索引结构还是hash map。这样的存储形式就被成为SSTable(排序字符串表)。SSTable相对于单纯顺序添加的形式有以下几个优点:
1、在合并冻结段时更高效,由于每个段中的key都是有序的,合并时方法类似与归并排序merge sort的方式
 2、不需要把段文件中每个key的偏移量都存进内存的hash map中,例如,如果当前查找的键handiwork,且不知道该键在段文件中的确切偏移量,但是如果知道键handbag和键handsome的偏移量,由于键在段文件中时有序的,可以跳到handbag的偏移,从那里开始顺序扫描,直到找到handiwork。所以,虽然仍然需要内存的hash map做索引,但是它可以是稀疏的,而且由于顺序扫描可以很快的扫描几千个字节,所以通常对于一个段文件,只需要每隔几千个字节选一个key添加到内存中的hash map做索引即可。
2、不需要把段文件中每个key的偏移量都存进内存的hash map中,例如,如果当前查找的键handiwork,且不知道该键在段文件中的确切偏移量,但是如果知道键handbag和键handsome的偏移量,由于键在段文件中时有序的,可以跳到handbag的偏移,从那里开始顺序扫描,直到找到handiwork。所以,虽然仍然需要内存的hash map做索引,但是它可以是稀疏的,而且由于顺序扫描可以很快的扫描几千个字节,所以通常对于一个段文件,只需要每隔几千个字节选一个key添加到内存中的hash map做索引即可。