成对使用new和delete时要采用相同形式
如果你在new表达式中使用[ ],必须在相应的delete表达式中也使用[ ]。如果你在new表达式中不使用[ ],一定不要在相应的delete表达式中使用[ ]。
另外尽量不要对数组形式做typedef动作,否则会导致new和delete的不匹配。例如:
1 | typedef std::string Address[4];//用四个字符串来表示地址 |
该条款针中的资源指的是用户动态申请的资源。看一个例子:
假设有一个工厂函数,用于生产某特定的Investment对象
1 | class Investment { ... }; |
在上例中,如果用户不知道createInvestment的内部实现,那么就不知道Investment是动态创建出来的,另外如果用户知道createInvestment是动态创建出来的,也很有可能忘记了要delete。所以好的方式是利用非动态对象来管理动态申请的资源,利用非动态对象的析构函数来释放资源。
1 | int main() { |
这种其实还有一个问题,就是用户很有可能忘记使用share_ptr来管理,所以最好直接让工厂函数返回一个shared_ptr。
1 | std::shared_ptr<Investment> createInvestment() { |
通常使用shared_ptr和unique_ptr就可以完成对动态申请的资源进行管理,但是某些情况下可能需要自己设计一个用于管理动态资源的对象。
如果自己不定义copy构造函数和copy assignment操作函数的话,编译器提供的copy构造函数和copy assignment操作符函数会自动对其基类部分进行copy构造和copy assign,但是如果自己定义了copy构造函数和copy assignment操作函数的话,那么就要在这两个函数中对基类进行复制。
例子:
1 | class Base { |
在使用c++多态特性的时候,通常会用基类指针或者基类引用来指向派生类对象,如果派生类对象是动态创建出来的,当delete的时候传入的是基类指针,如果析构函数是non-virtual的话,那么就可能出现属于派生类对象的部分未被析构的情况。因此,任何class只要带有virtual函数都几乎确定应该有一个virtual析构函数。
但是无端地将所有class的析构函数函数声明为virtual,也是错误的。在c++中所有STL容器如vector,list,set,map等都是不带virtual析构函数的class。
比如有时候你希望拥有抽象class,但是手上没有任何pure virtual函数时,可以将该类的析构函数声明为pure virtual函数,然而这里有个窍门:你必须为这个pure virtual析构函数提供一份定义,因为抽象class的析构函数仍会在派生类的析构函数中被调用,如果不提供定义,那么连接器就会报错。
给base class一个virtual析构函数,这个规则只适用于有多态性质的base class
在class中,如果你自己没声明,编译器会为一个类自动声明(编译器版本的)一个默认构造函数,一个copy构造(拷贝构造)函数和一个copy assignment(拷贝赋值)操作符函数,这些函数都是public且inline的。但是只有当这些函数被调用了,它们才会被编译器创建出来。另外编译器还会提供一个默认的析构函数,这个析构函数是non-virtual的,除非这个class的base class自身声明有virtual 析构函数。
对于编译器提供的copy构造函数和copy assignment操作符函数,都只是单纯地将来源对象的每个non-static成员变量进行浅拷贝到目标对象。
给定训练样本集$D= {(xi, y_i)}{i=1}^m, y_i \in {-1, +1}$,分类学习最基本的思想就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开,但能将样本分开来的超平面可能有很多。例如:
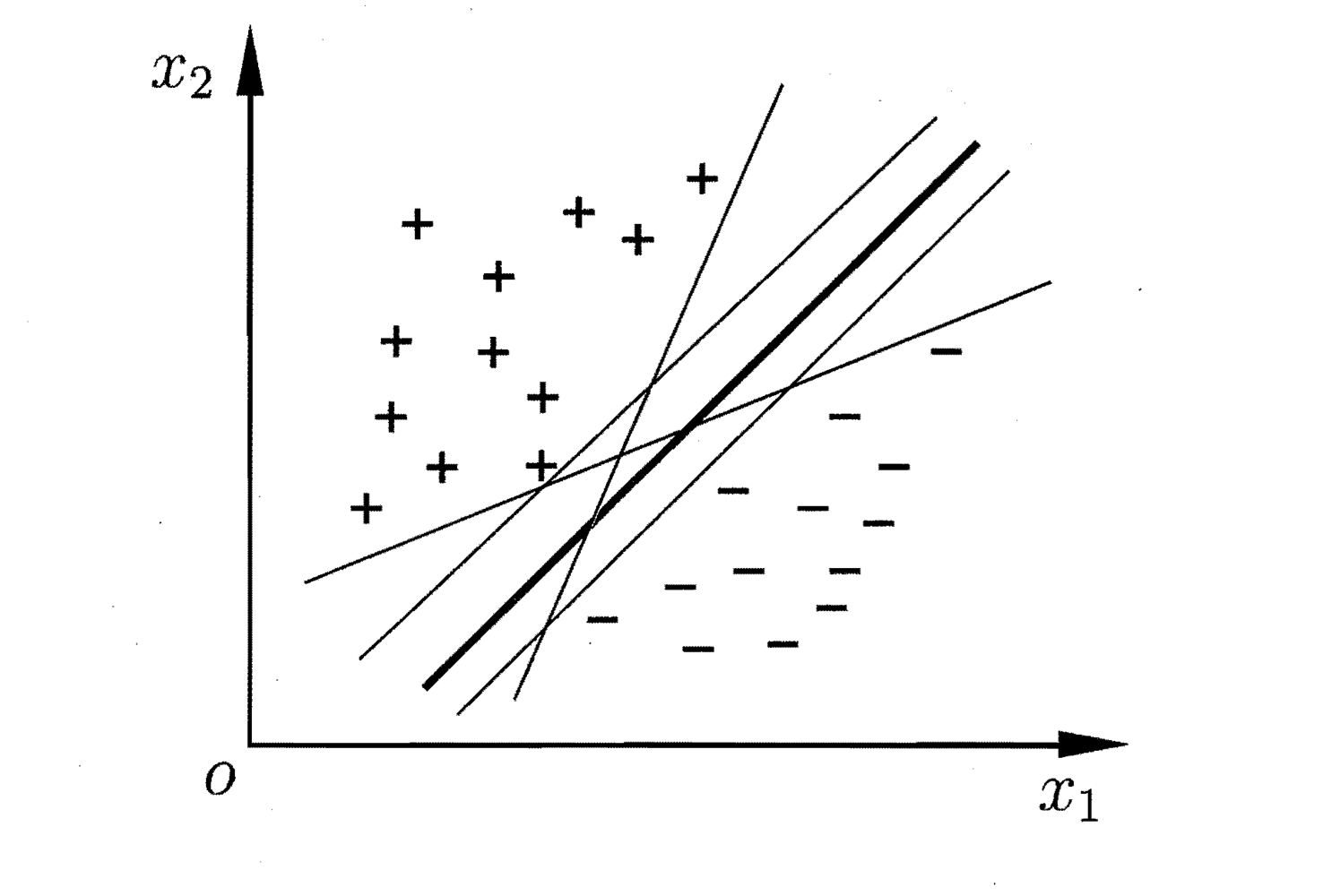
对于上图,直观上看,应该去找位于两类训练样本“正中间”的划分超平面,因为该划分超平面对训练样本局部扰动的“容忍”性最好。例如,由于训练集的局限性或噪声的因素,训练集外的样本可能比上图中的训练样本更接近两个类的分隔界,而粗线的超平面受影响最小,因此其对未见示例的泛化能力最强。
在样本空间中,划分超平面可通过如下线性方程来描述:
其中$w = (w_1, w_2, \cdots, w_d)$为法向量,决定了超平面的方向,$b$为位移项,决定了超平面与原点之间的距离(其实二维平面上的直线$y = kx + b$本质上也是法向量的形式,其可以转换成$kx - y + b = 0$,即$(k, -1)(x, y)^T + b = 0$)。显然,划分超平面可被法向量$w$和位移$b$确定,下面我们将其记为$(w, b)$,样本空间中任意点$x$到超平面$(w, b)$的距离可写为:
假设超平面$(w, b)$能将训练样本正确分类,即对$(x_i, y_i) \in D$,若$y_i = +1$,则有$w^T x_i + b > 0$(在超平面上方);若$y_i = -1$,则有$w^T x_i + b < 0$(在超平面下方)。令
即找到那些使得所有样例到平面的距离都大于1的平面
可以证明,如果存在超平面$(w, b)$能将训练样本正确分类,则总存在缩放变换,使得上式成立,即总存在满足上式的超平面。下图是一个例子:
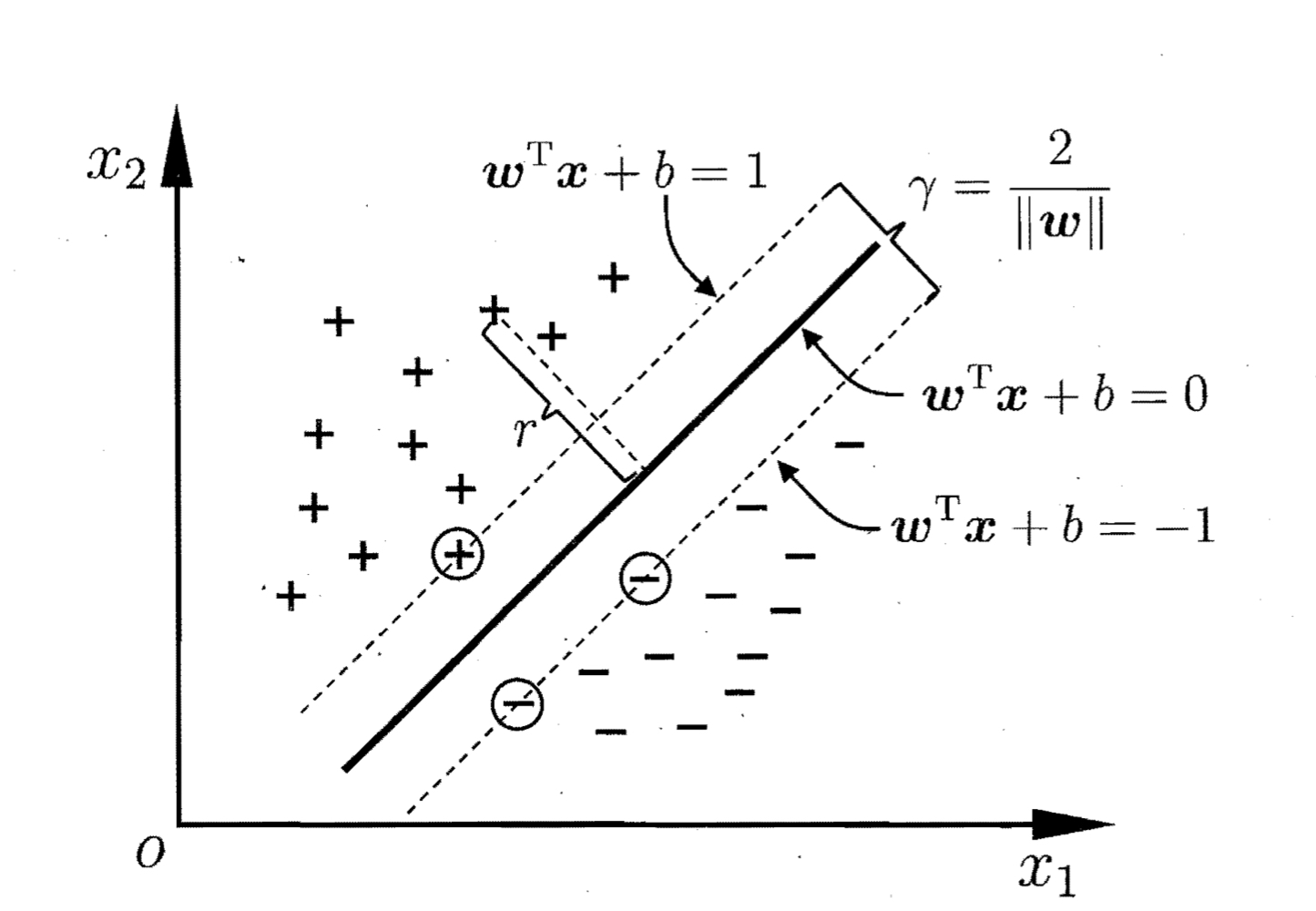
在上图中,距离超平面最近的几个训练样本点被称为“支持向量”,两个异类支持向量到超平面的距离之和称为“间隔”,在上图中,间隔为$\gamma = \frac{2}{||w||}$。
欲找到具有“最大间隔”的划分超平面,也就是要找到能满足(1)式约束的$w、b$,使得距离$\gamma$最大,即
显然为了最大化间隔,仅需要最大化$||w||^{-1}$,这等价于最小化$||w||^2$,于是,上式可重写为
这就是支持向量机的基本型